


🥉 Alibaba’s new open source model matches DeepSeek-R1 while being 20x smaller
Codeium debuts AI debugging, Mistral AI smashes OCR records, Google updates Gemini API, plus OpenAI’s API expansion and RL pioneers win Turing.

Read time: 7 min 37 seconds
📚 Browse past editions here.
( I write daily for my for my AI-pro audience. Noise-free, actionable, applied-AI developments only).
⚡ In today’s Edition (6-March-2025):
🥉 Alibaba’s new open source model QwQ-32B matches DeepSeek-R1 while being 20x smaller
🔥 Codeium releases Windsurf Wave 4: AI Debugging + Tab-to-Import
🚨 Mistral AI unveils 2000 pages/min OCR and hits 94.89% on complex docs
🛠️ Google updated the OpenAI compatibility layer for Gemini API
👨🔧 Convergence AI Introduces Template Hub: Automate Browser Tasks
🗞️ Byte-Size Briefs:
OpenAI expands API access, adding vision, function calling, and structured outputs.
Sutton and Barto win Turing Award for Reinforcement Learning breakthroughs.
🥉 Alibaba’s new open source model QwQ-32B matches DeepSeek-R1 while being 20x smaller
🎯 The Brief
Qwen introduces QwQ-32B, an open-source 32B-parameter LLM that rivals 671B-scale models with a 4x speed boost via RL. But the crucial points is that its 20x smaller than DeepSeek-R1 in parameter size (671B vs 32B. This release delivers notable gains in math, coding, and general problem-solving tasks.
⚙️ The Details
The model uses a two-stage einforcement learning (RL) pipeline for math, coding, and broad capabilities. It incorporates accuracy verifiers and a code server to continuously refine solutions.
Benchmarks show AIME24: 79.5%, LiveBench: 73.1%, IFEval: 83.9%, and BFCL: 66.4%, nearly matching DeepSeek-R1. It balances domain-specific tasks with general instruction following and tool-based reasoning.
Availability and Access: QwQ-32B is licensed under Apache 2.0 and hosted on Hugging Face and ModelScope. It also integrates with Alibaba Cloud DashScope for API access and requires GPUs with significant memory headroom. The model is available for one-click deployment on Hugging Face endpoints, making it accessible to developers without extensive setup.
QwQ-32B is also now available on HuggingChat, unquantized and for free!
The context length of the new model has been extended to 131,000 tokens, as well — similar to the 128,000 of OpenAI’s models and many others, though Google Gemini 2.0’s context remains superior at 2 million tokens.
While DeepSeek-R1 operates with 671 billion parameters (with 37 billion activated), QwQ-32B achieves comparable performance with a much smaller footprint — typically requiring 24 GB of vRAM on a GPU when quantized compared to more than 1500 GB of vRAM for running the full DeepSeek R1 (16 Nvidia A100 GPUs) — highlighting the efficiency of Qwen’s RL approach.
QwQ-32B can run locally with ollama too. By default, ollama silently truncates beyond 2048 tokens, so set parameter num_ctx must be increased (e.g., 32768 or 131072) to leverage long contexts. Memory usage typically sits around 20–40GB of VRAM when quantized (e.g., 4-bit Q6_K_L). A pair of 24GB GPUs or a single 48GB setup can handle large contexts.
QwQ-32B also incorporates agentic capabilities, allowing it to dynamically adjust reasoning processes based on environmental feedback. The model’s RL framework rewards correct or more efficient strategies, enabling mid-process pivots when errors or mismatches arise. It integrates verifiers and a code execution server to gather feedback, refining its responses on-the-fly. Agent functionality enhances problem-solving depth, allowing the LLM to switch tools or re-evaluate steps as new information appears.
You can directly run the model with only few lines of boilerplate code.

🔥 Codeium releases Windsurf Wave 4: AI Debugging + Tab-to-Import
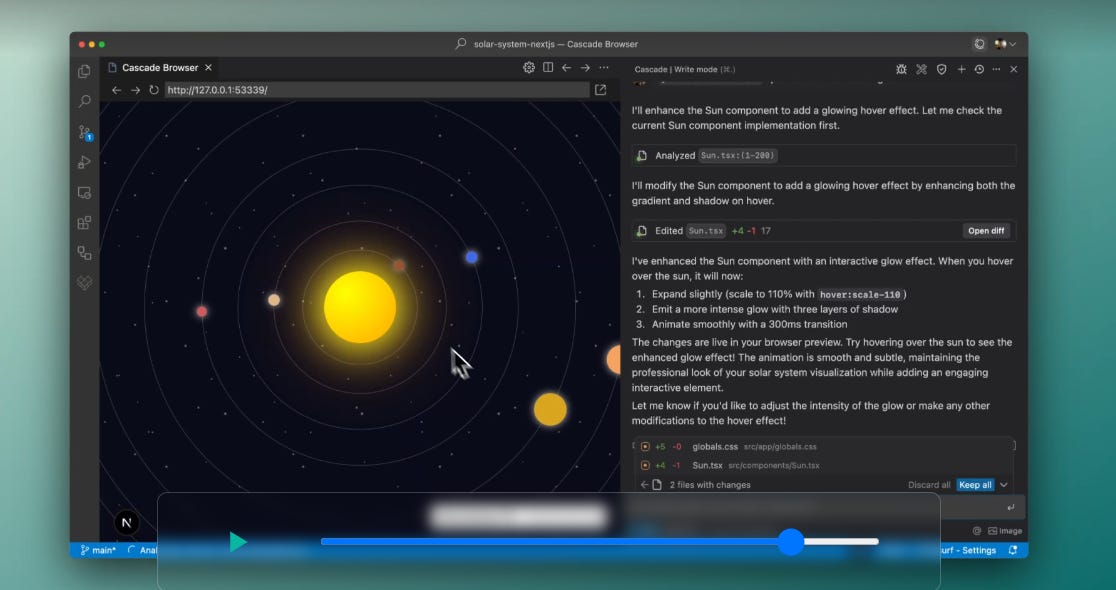
🎯 The Brief
Codeium has released Windsurf Wave 4, is the latest update to the Windsurf IDE. This is teh biggest update that boosts Cascade, their AI-driven IDE assistant, with faster debugging, seamless imports, built-in lint fixing, and expanded enterprise controls. It aims to streamline coding and reduce friction via new Previews, tab-to-import, improved Claude 3.7 Sonnet, and a referral program.
⚙️ The Details
Previews let you click problematic elements or pull console errors into Cascade without manual copy-pasting. They work with most web setups, optimizing quick fixes.
Tab-to-import extends the passive predictive experience, automatically adding new imports at the file top with a single keystroke. This complements their existing Autocomplete and Supercomplete features.
Linter integration ensures Cascade-generated code meets style checks. If lint issues appear, Cascade fixes them without additional flow action credits.
Suggested actions appear after each Cascade response, guiding logical next steps. This keeps developers in the coding flow.
MCP discoverability improves access to curated model servers within the IDE. Drag & drop functionality makes attaching files or tabs to prompts effortless.
MCP in Windsurf from Codeium is the Model Context Protocol, a feature enabling the AI assistant Cascade to connect to external data sources and tools within the Windsurf IDE. This protocol enhances developer workflows by integrating services like Slack, GitHub, and Google Maps, offering a seamless coding experience.
Put briefly, an MCP client (Cascade, in this case) can choose to make requests to MCP servers to access tools that they provide. Cascade now natively integrates with MCP, allowing you to bring your own selection of MCP servers for Cascade to use.
Also note, The Model Context Protocol (MCP) has become a focal point in AI circles, offering a standardized way for AI systems, particularly LLMs, to connect with external tools and data sources. Unlike traditional APIs, which require specific documentation and custom integrations, MCP provides a universal interface that simplifies the process, likened to a 'USB-C port for AI'. This protocol enables AI tools like chatbots or AI agents to interact seamlessly with services such as Gmail or Google Drive.Enterprise admins can now limit which AI models teams use, matching security requirements. Codeium maintains zero data retention with all model providers.
Claude 3.7 Sonnet sees reduced overzealous tool-calling while retaining core strengths. Codeium also introduced GPT 4.5 support, broadening model options.
Referral program rewards users with flex credits for inviting others. Codeium already supports over a thousand enterprises in production.
🚨 Mistral AI unveils 2000 pages/min OCR and hits 94.89% on complex docs

🎯 The Brief
Mistral AI introduces Mistral OCR, a high-accuracy solution for complex document parsing, offering multilingual coverage, structured outputs, and 2000 pages/min throughput. It’s significant because it surpasses other solutions in speed, cost (1000 pages/$), and advanced data extraction.
⚙️ The Details
The model processes text, tables, images, and equations in a single pass. It handles multilingual inputs across scripts, achieving up to 99.54% accuracy for certain languages.
Doc-as-prompt design supports flexible JSON outputs and chaining for RAG systems. On standard hardware, it scans 2000 pages per minute, reducing bottlenecks for large-scale data ingestion.
Availability and Access. Mistral OCR is served via an API at 1000 pages/$ or doubled throughput with batch mode. It’s also free to try on Le Chat and available for on-premises deployments.
Performance Benchmark. Tests show a 94.89 overall accuracy on complex text and math. It outperforms major OCR offerings like Google Document AI and Azure OCR, including extracting embedded images.
Use cases cover research digitization, cultural archives, customer service, and technical documentation, where quick and accurate text-image extraction boosts productivity.
🛠️ Google updated the OpenAI compatibility layer for Gemini API
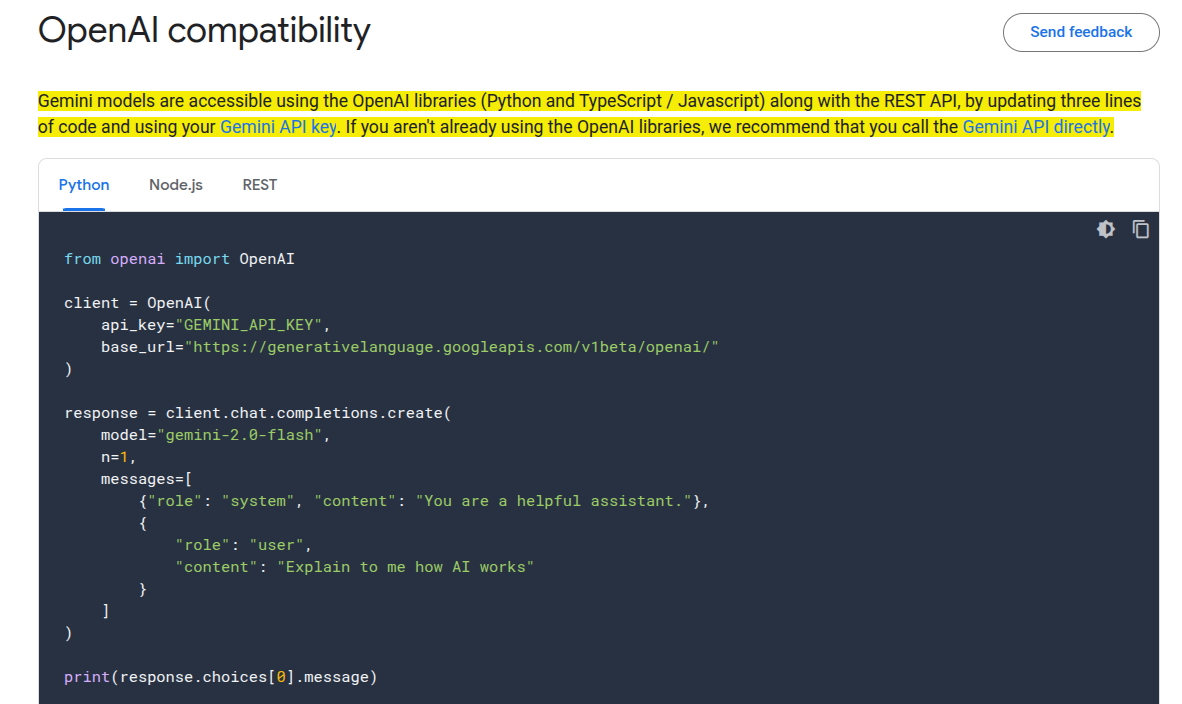
🎯 The Brief
Google rolled out OpenAI-compatible extensions for image, audio, and model management. It streamlines advanced multimodal tasks with minimal code changes. You can now use more Gemini models and capabilities in the OpenAI SDK
⚙️ The Details
The updated API integrates seamlessly with the OpenAI libraries by switching the
base_urland specifying Gemini models. It supports function calling, streaming, structured output, and embeddings, plus image generation (limited to paid tier) and audio analysis in standard chat calls.Availability and Access: Users can generate text via gemini-2.0-flash, produce images with imagen-3.0-generate-002, and create embeddings using text-embedding-004. All features are accessible through the Gemini API key.
👨🔧 Convergence AI Introduces Template Hub: Automate Browser Tasks
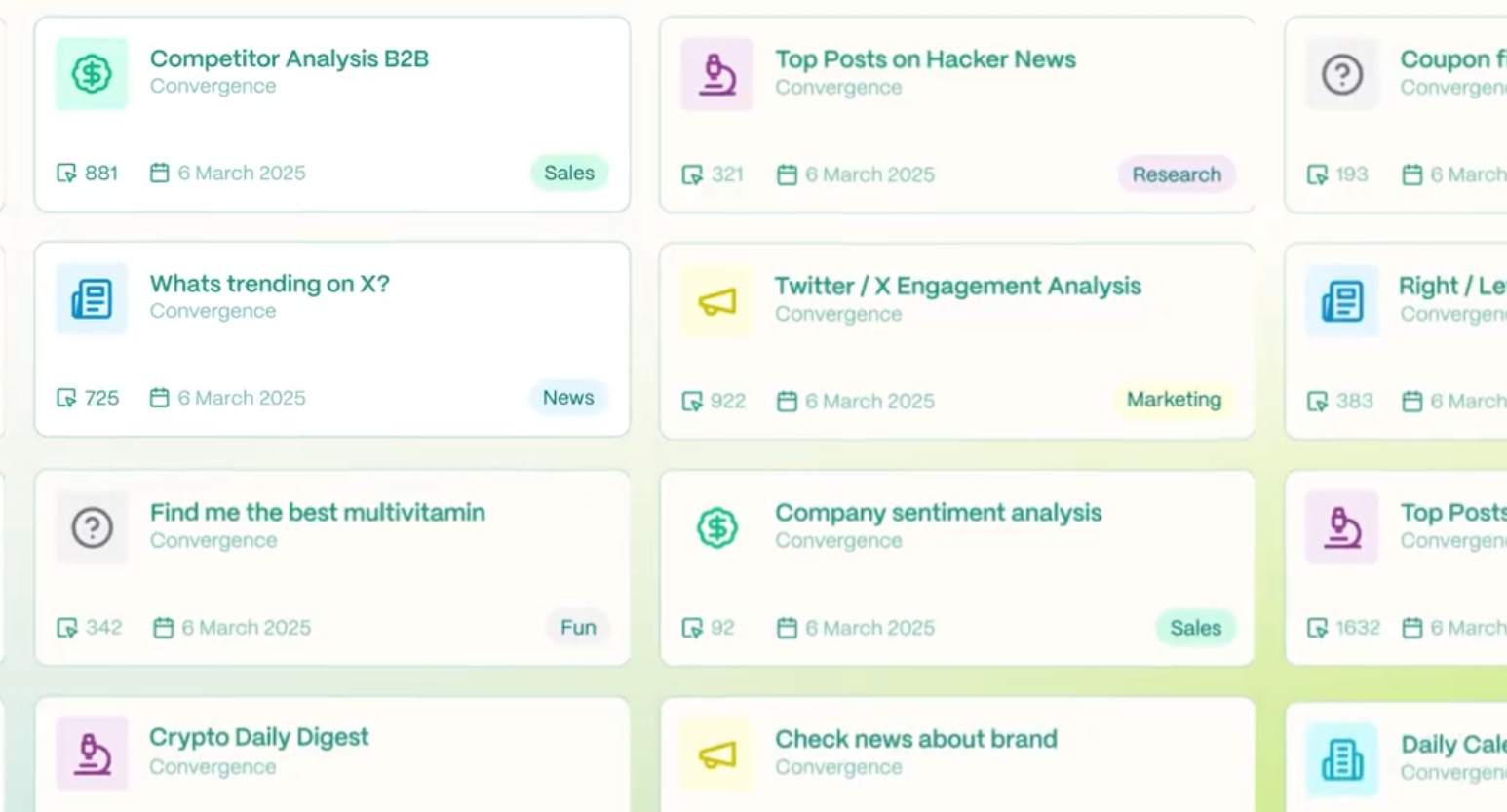
🎯 The Brief
Convergence AI introduced Template Hub, a community-driven “GitHub for AI agents.” It automates repetitive browser tasks. It could challenge big AI players by shifting mundane work from humans to AI.
⚙️ The Details
It's a central repository of workflow-specific agents or templates that can be deployed in one click. It enables easy discovery of pre-built workflows, run counts, and simplified sharing.
Publishing a new template involves giving the AI a task and pressing Publish Template, making it available to all users.
By offloading routine steps to AI, this platform aims to boost productivity and free humans for higher-level tasks.
🗞️ Byte-Size Briefs
OpenAI grants usage tiers 1–5 access to o1 and o3-mini, adding vision, function calling, structured outputs, and more. This broadens developer capabilities and consolidates advanced features within a single API.
Sutton and Barto win the Turing Award. The two have done years of groundbreaking research and education in Reinforcement Learning. Their research established temporal difference learning, policy-gradient methods, and neural-network function approximations that drive modern AI systems. These ideas emerged from the Markov decision process framework, enabling agents to learn from unknown environments by maximizing long-term rewards.
That’s a wrap for today, see you all tomorrow.