


Chinese AGI lab achieves remarkable cost efficiency: $5.5M training for Claude-competitive model: DeepSeek-V3
DeepSeek-V3: China's Leap in AI, new open source model was trained for just $5.5M, and that it’s on par with GPT 4o and Claude 3.5 Sonnet.

Read time: 6 min 22 seconds
⚡In today’s Edition (26-Dec-2024):
🎖️Chinese AGI lab achieves remarkable cost efficiency: $5.5M training for Claude-competitive model
🔥 Nvidia is expected to its next-generation GB300 & B300 GPUs, delivering 50% higher FLOPS at GTC 2025
📹 Alibaba announces advanced experimental visual reasoning QVQ-72B AI model
🗞️ Byte-Size Brief:
According to a report by theinformation, Microsoft and OpenAI are currently negotiating changes to their partnership terms. And they seem to have defined AGI, as a moment when it can generate $100bn in profit (as per the report) .
🎖️Chinese AGI lab DeepSeek achieved insanely low training cost of only $5.5 million for their new v3 model, which matches Claude 3.5 sonnet performance
🎯 The Brief
DeepSeek unveils DeepSeek-V3, a groundbreaking 671B-parameter MoE LLM with only 37B activated parameters, achieving state-of-the-art performance while drastically reducing training costs to just $5.5M. Delivers 3x faster inference at 60 tokens/second compared to V2.
👨🔧Can I run DeepSeek-V3 locally?
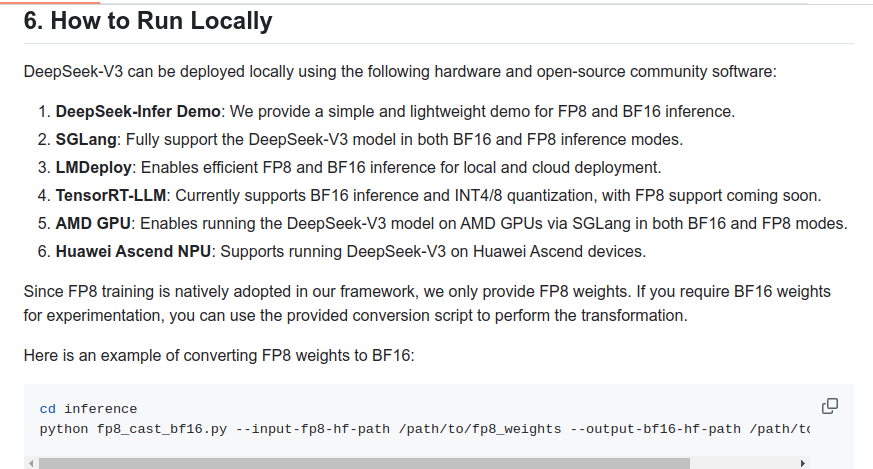
The model will take at least 350-700 GB of RAM/VRAM (depends on quant), given its 671B parameters size, (for context, the largest Llama is 405B).
The total size of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the Main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights.
You aren't force to use VRAM here, because DeepSeek V3 has 37B active parameters which means it will perform at usable speeds with CPU-only inference. The only problem is that you still need to have all parameters in RAM.
This model is 671B parameters; even at 4bpw you are looking at 335.5GB just for the model alone, and then you need to add more for the kv cache. So Macs are also out of the question unless Apple comes out with 512GB models.
⚙️ The Details
→ The whole training only cost $5.576 million or ~55 days on a 2048xH800 cluster. This is TINY compared to the Llama, GPT or Claude training runs.
Total Cost: $5.576 million breakdown:
Pre-training: $5.328M (2664K GPU hours)
Context extension: $0.238M (119K GPU hours)
Post-training: $0.01M (5K GPU hours)
Efficiency Innovations
→ The cost efficiency stems from three key technical advances:
Architecture Optimization:
MoE architecture with 671B total parameters
Only 37B activated parameters per token
256 routed experts with 1 shared expert
Training Optimizations:
FP8 mixed precision framework: First validation of FP8 training on an extremely large-scale model, improving efficiency
DualPipe algorithm for computation-communication overlap. Enabling computation-communication overlap and reducing pipeline bubbles.
Auxiliary-loss-free load balancing: Introduced an auxiliary-loss-free approach to minimize performance degradation while ensuring load balancing
Training on 14.8T tokens with high efficiency
Resource Utilization:
Each trillion tokens requires only 180K H800 GPU hours
Pre-training completed in less than two months
Achieves 3x faster inference than previous version
This represents a step-change in training efficiency compared to other major models, achieving comparable performance at a fraction of the traditional training cost.
For context, META's Llama 3 compute expenditure (39.3M H100 hours) could have yielded approximately 15 DeepSeek-V3 training cycles, yet DeepSeek achieved superior results with just 2.6M H800 hours.
Architecture:
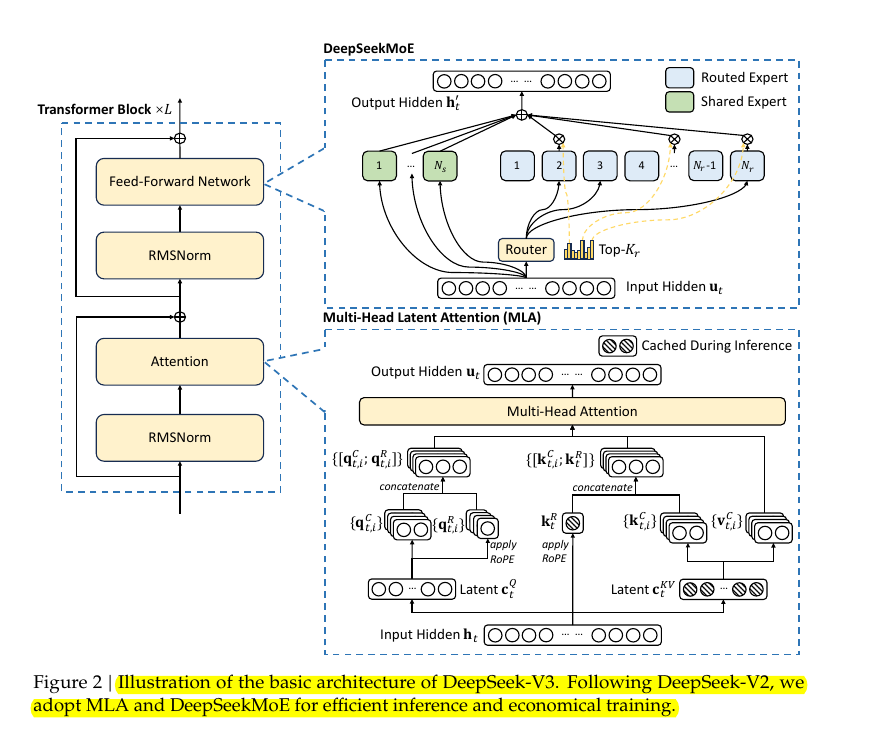
→ Architectural innovations include Multi-head Latent Attention and an auxiliary-loss-free load balancing strategy, featuring 256 routed experts and 1 shared expert with 8 active experts per token. The model introduces FP8 mixed precision training with high-precision accumulation.
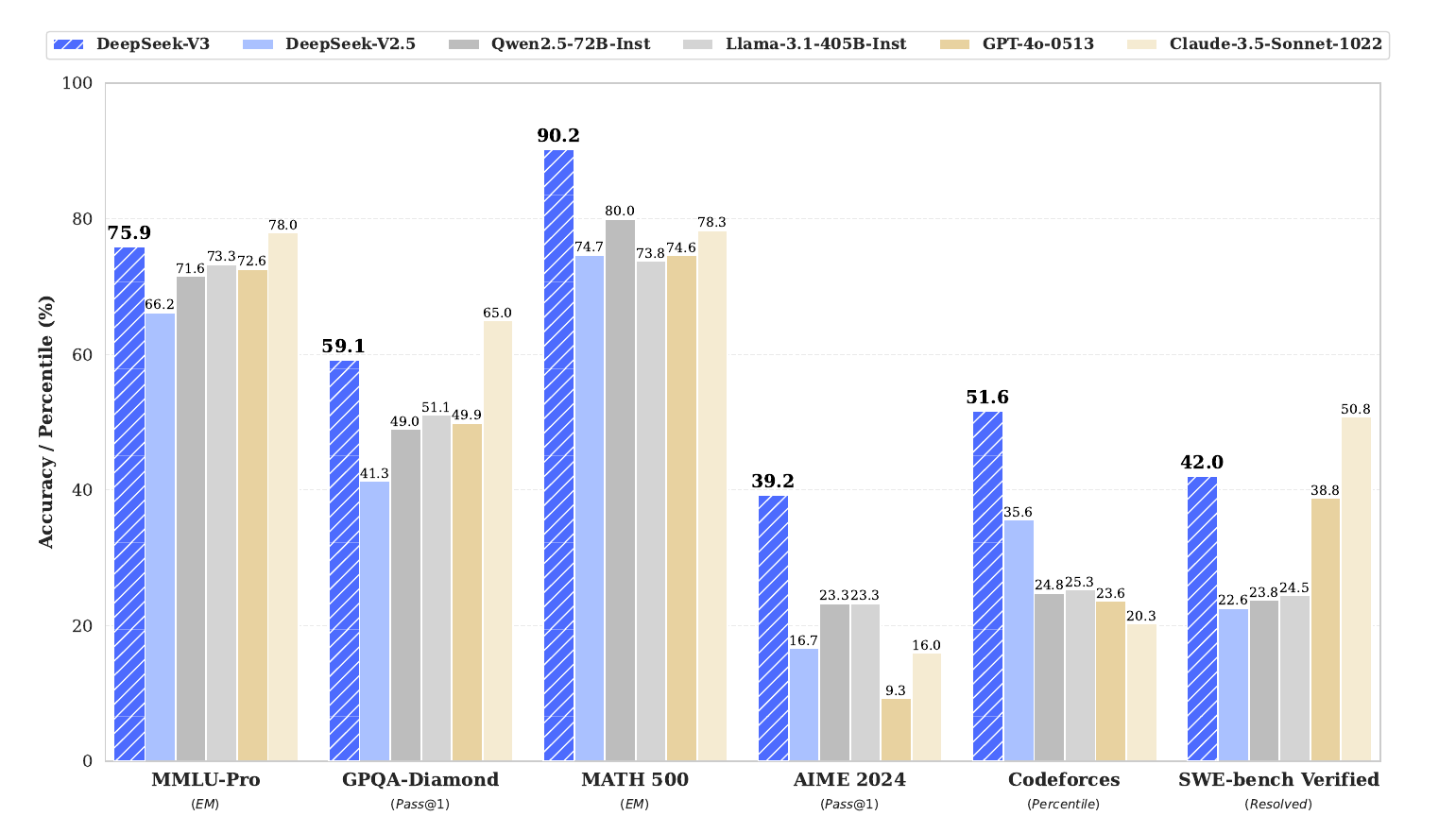
→ Performance benchmarks showcase excellence in technical tasks: 90.2% on MATH-500, 65.2% on HumanEval, and 51.6% on Codeforces. Matches or exceeds closed-source models like GPT-4o and Claude 3.5 Sonnet on many evaluations.
→ Implementation features 128k context length through two-stage extension, and employs multi-token prediction for improved training efficiency. Model maintains strong performance across English, Chinese, and multilingual tasks.
→ The key innovation here is the "complete causal chain" - each prediction takes into account all previous predictions, creating a more coherent and contextually aware sequence of predictions. This enables DeepSeek-V3 to generate text more efficiently by predicting multiple tokens in parallel while maintaining high accuracy.
Analyzing the number of Experts in this model
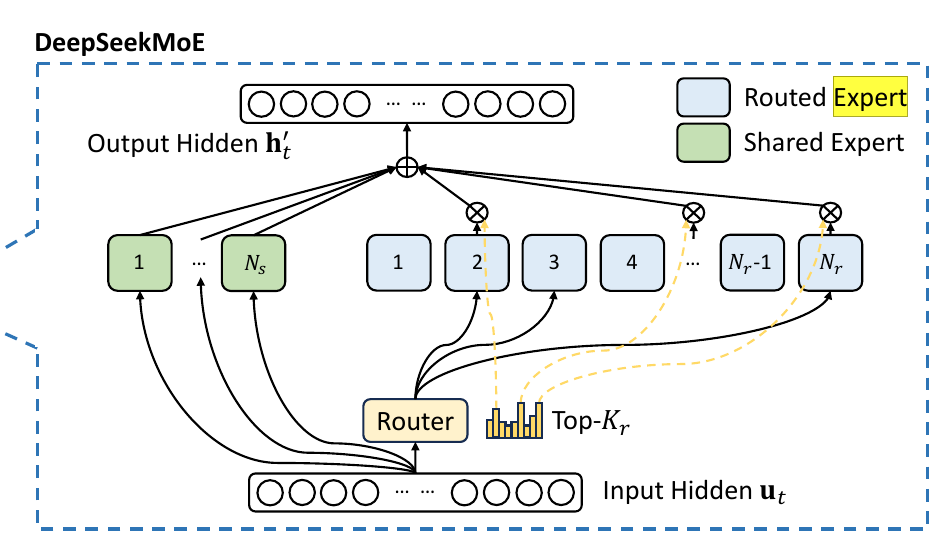
The model employs a dual-category expert system:
Shared Experts (Ns)
Displayed in green blocks on the left
Number: 1 shared expert
These experts process all inputs, providing baseline computational capability
Routed Experts (Nr)
Displayed in gray blocks on the right
Number: 256 routed experts
The router dynamically selects top-Kr (8) experts for each token
So here we have 257 experts in total. Each token is routed to 8 specialized experts and 1 shared expert, which is 9 out of 257 overall. That translates to about 1 / 28.6 of the experts being active for each token.
A sparsity factor of ~28.6x in a Mixture-of-Experts (MoE) model can be beneficial if the gating mechanism is well-trained and routes tokens to the most appropriate experts. This approach can reduce the computational burden on each forward pass since tokens avoid passing through all experts at once, effectively lowering the capacity requirements for each inference step. However, an extremely high sparsity factor can introduce complexity in balancing expert utilization, as some experts might receive significantly more workload than others if the gating is not carefully managed.
With a high number of experts, the model’s overall capacity is large, but the active set per token remains small. This is often a desirable property in MoE setups because it keeps the per-token computation more manageable without sacrificing the total parameter count.
The optimal performance with this model depends on the hardware resources, training stability, and the distribution of expert usage across domains. If the gating remains stable and properly balanced, this level of sparsity can lead to stronger performance and lower compute overhead compared to fully dense alternatives.
🔥 Nvidia is expected to its next-generation GB300 & B300 GPUs, delivering 50% higher FLOPS at GTC 2025

🎯 The Brief
Nvidia is expected to its next-generation GB300 & B300 GPUs, delivering 50% higher FLOPS vs B200 through architectural enhancements and 200W additional power, pushing TDP to 1.4KW for GB300, at GTC 2025 (March 17-20). It will transform AI inference capabilities through modular design and enhanced memory architecture, while restructuring supply chain dynamics for improved hyperscaler customization.
⚙️ The Details
→ The new architecture delivers 50% higher FLOPS through TSMC 4NP process optimization and 200W additional power, pushing TDP to 1.4KW for GB300. Memory capacity jumps to 288GB with 12-Hi HBM3E, maintaining 8TB/s bandwidth per GPU.
→ Supply chain transforms with modular SXM Puck design, shifting from Wistron/FII monopoly to open ecosystem. Hyperscalers gain control over mainboard design, cooling systems, and power delivery while standardizing GPU interfaces.
→ Performance gains include 43% higher interactivity across batch sizes and ~3x cost reduction through expanded memory capacity. NVL72 enables 72 GPUs to share memory at low latency, supporting 100k+ token reasoning lengths.
→ ConnectX-8 integration doubles scale-out bandwidth on InfiniBand and Ethernet, with 48 PCIe lanes enabling unique architectures for air-cooled configurations.
📹 Alibaba announces advanced experimental visual reasoning QVQ-72B AI model
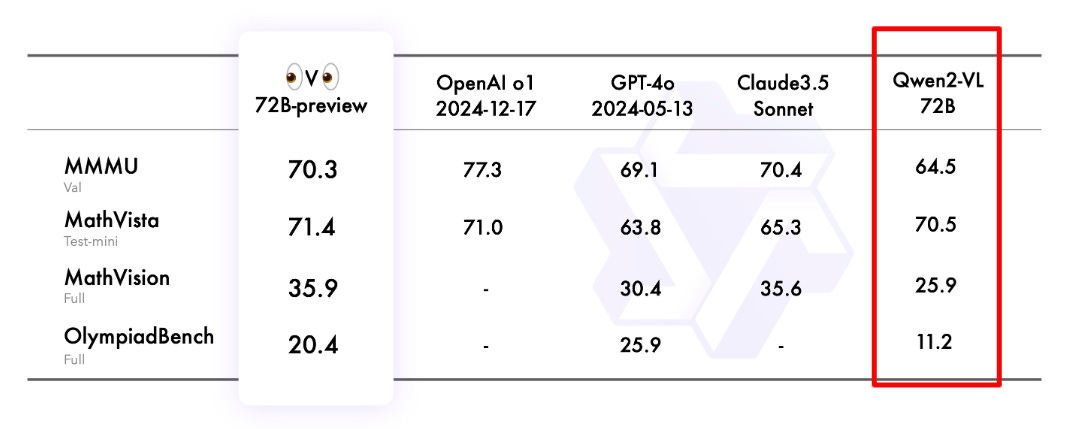
🎯 The Brief
Qwen Team releases QVQ-72B-Preview, a multimodal reasoning model built on Qwen2-VL-72B, achieving 70.3 score on MMMU benchmark. The model excels at visual reasoning tasks and demonstrates enhanced capabilities in mathematics and science problem-solving.
⚙️ The Details
→ QVQ represents advancement in AI's visual understanding capabilities, integrating language and vision for improved reasoning. The model demonstrates exceptional performance across four benchmark datasets: MMMU, MathVista, MathVision, and OlympiadBench.
→ Core performance metrics show QVQ outperforming its predecessor with scores of 71.4 on MathVista, 35.9 on MathVision, and 20.4 on OlympiadBench. The model effectively closes performance gaps with leading state-of-the-art models.
→ Notable limitations include language mixing issues, recursive reasoning patterns, potential loss of visual focus during multi-step tasks, and safety considerations requiring enhanced measures for deployment.
→ Development roadmap focuses on integrating additional modalities into a unified model for enhanced deep thinking and reasoning capabilities based on visual information.
→ “Imagine an AI that can look at a complex physics problem, and methodically reason its way to a solution with the confidence of a master physicist,” the Qwen team said about the release. “This vision inspired us to create QVQ.
🗞️ Byte-Size Brief
According to a report by theinformation, Microsoft and OpenAI are currently negotiating changes to their partnership terms, focusing on Microsoft's equity stake, cloud computing deals, revenue sharing, and intellectual property rights. And as per this report, "AGI will be achieved only when OpenAI develops systems capable of generating maximum total profits, and that number is close to $100 billion."
Detailed breakdown. Thank you for sharing. DeepSeek's incredible cost-cutting method will be studied, and I believe your post will be the one of the stops on the journey for study.