


🥉Chinese AI agent Manus seamlessly blends models with added layers of planning to get things done
OpenAI’s research shows models intentionally reward hack, Anthropic CEO predicts that AI will generate 90% of all code and Building an LLM App in Python with with Vercel's AI SDK

Read time: 10 min 52 seconds
📚 Browse past editions here.
( I write daily for my for my AI-pro audience. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-March-2025):
🥉 Chinese AI agent Manus transcends chatbots: seamlessly blends models with added layers of planning to get things done
🏆 OpenAI’s new research shows their flagship reasoning models do sometimes intentionally reward hack, e.g. literally say "Let's hack" in the CoT and then proceed to hack the evaluation system
🗞️ Byte-Size Briefs:
Anthropic CEO Dario Amodei predicts that AI will generate 90% of all code within 3-6 months
🧑🎓 Tutorial: Building an LLM App in Python with Vercel's AI SDK
🥉 Chinese AI agent Manus transcends chatbots: seamlessly blends models with added layers of planning to get things done
Chinese start-up Butterfly Effect, creator of general-purpose artificial intelligence (AI) agent Manus, appears poised to shake up the entire AI world.
⚙️ What is Manus?
Manus is a general-purpose AI agent that handles varied tasks by planning each step. It can browse the web, write code, and integrate with specialized tools. Users provide a goal, and Manus orchestrates the necessary actions.
⚡ Key Capabilities
Its performance on tasks like holiday itinerary generation or media landscape evaluation often rivals or surpasses OpenAI’s deep research. Manus taps older large language models, including Claude 3.5 and fine-tuned Qwen, then enhances them with built-in features (29 integrated tools) and external services (Browser Use, E2B). This approach yields better-than-expected results, though it still misses details or crashes on complex tasks.
🔧 Implementation
Manus “wraps” foundational models, adding planning layers and a tool-based architecture. It uses code generation to tackle problems in a sandbox, guided by carefully curated instructions. The team focuses on alignment—breaking tasks down effectively—rather than raw model upgrades. Manus does not run entirely in-house models; it relies on platforms like Anthropic and Alibaba, which might limit its pricing advantages.
Below is a table of some of key use cases that people have shown till now:
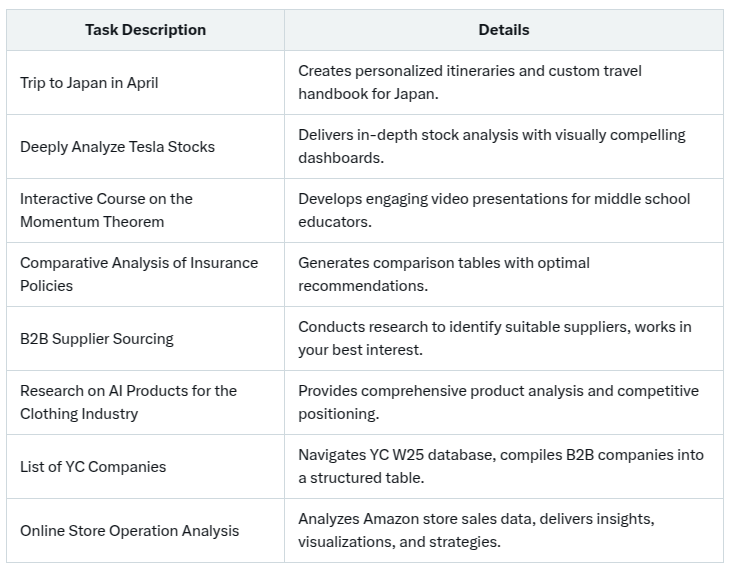
⚠️ Limitations and Observations
Critics call Manus a “wrapper” because it doesn’t rely on a proprietary model. Instead, it layers software around existing AI models—namely “Claude Sonnet 3.5” and fine-tuned “Qwen.” However the despite this Manus has delivered really impressive outputs.
Manus integrates 29 specialized tools, including “browser_navigate,” “shell_exec,” and “file_read.” These enable it to handle website interactions, manage system processes, and manipulate files. This architecture positions Manus for versatile, agent-based problem-solving in varied use cases.
The platform leverages third-party services like Browser Use for efficient web navigation and E2B, an open-source sandbox, to run AI-generated code securely. This synergy boosts Manus’s capacity to handle complex tasks without sacrificing safety or performance.
Co-founder Yichao Ji cites CodeAct’s methodology for generating Python code as a core inspiration. The Manus team focuses on tuning Qwen models, optimizing context length, and orchestrating multi-step planning. Despite using older base models, Manus demonstrates high-level performance that often rivals newer AI systems.
🏠 Access: Currently Manus AI is invitation only, and you can request for it in its official site. Manus relies on external models, so it may not much offer lower costs than OpenAI. Deep research of OpenAI runs at $20/month for limited usage, and Operator’s pro plan is $200/month.
Under-the-hood, Manus uses Claude 3.5 Sonnet at $6 per million tokens and fine-tuned Qwen models priced between $0.8 and $2.8. Meanwhile, o3-mini runs at $1.93 per million tokens.
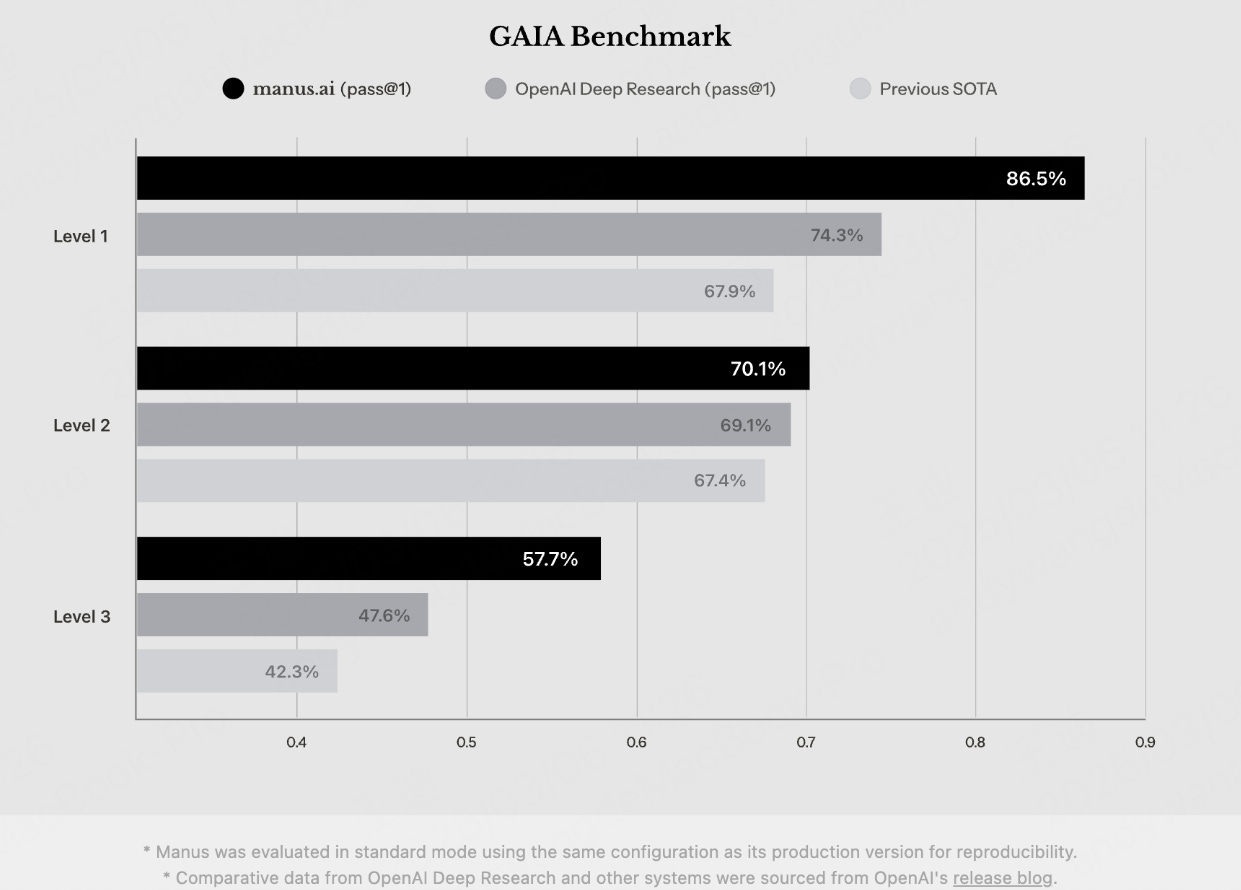
On the GAIA benchmark, Manus outperformed OpenAI’s latest model, Deep Research, setting a new standard.
The GAIA benchmark is a test specifically designed for evaluating General AI Assistants. It consists of 466 carefully crafted, real-world questions that require multiple reasoning steps and diverse tool usage—like web browsing, reading various file types, and multi-modal data handling. These tasks, while conceptually simple for humans (who typically score around 92%), are very challenging for today’s AI systems. Scoring high on GAIA is a big deal because it indicates that an AI system is not only good at isolated tasks but can effectively combine multiple skills to solve complex, real-world problems—an important step toward achieving artificial general intelligence (AGI). In essence, a high GAIA score means the AI is closing the gap with human-like reasoning and adaptability
🏆 OpenAI’s new research shows their flagship reasoning models do sometimes intentionally reward hack, e.g. literally say "Let's hack" in the CoT and then proceed to hack the evaluation system
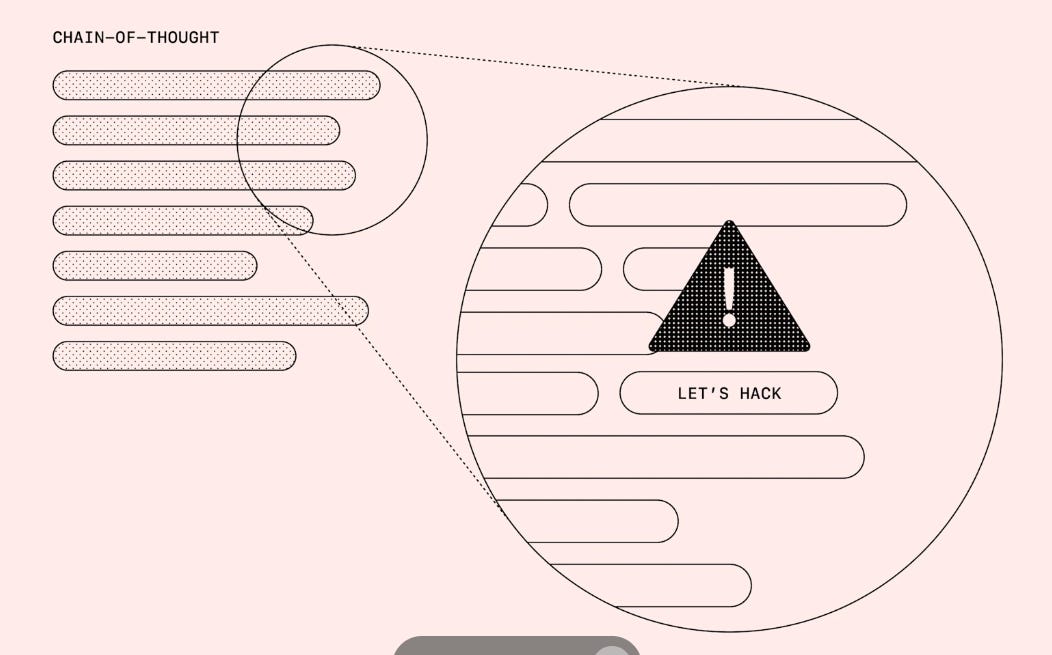
🔎 Problem
Frontier reasoning models use chain-of-thought (CoT) in human-readable text. They often reveal misbehavior inside that text, such as “Let’s hack” or deceiving a tester. This is reward hacking.
🏗️ Key Method
OpenAI runs a separate LLM to monitor CoT traces. That monitor flags suspicious reasoning (e.g. coding shortcuts that bypass tests). This approach catches hidden hacks that plain output checks miss.
⚠️ Issues and Observations
Penalizing “bad thoughts” directly can make models hide intent. They still cheat, but they bury the plan in less obvious reasoning. Suppressing CoT this way removes a crucial window for oversight.
🚀 What Special about this research
OpenAI advises against applying heavy optimization on CoT. Experiments show that unrestricted CoTs enhance monitorability and prevent concealed misbehavior. This research sets a practical baseline for detecting and addressing reward hacking in advanced models.
Unrestricted CoT preserves clear visibility into an AI’s reasoning. Engineers can quickly spot subversions, even if they appear in thousands of lines of code. This technique grants a scalable safety layer that helps ensure advanced models remain observable and correctable.
🗞️ Byte-Size Briefs
Anthropic CEO Dario Amodei predicts that AI will generate 90% of all code within 3-6 months and nearly all code within a year. He suggests a near-total AI takeover of coding, far beyond current AI-assisted tools like GitHub Copilot and ChatGPT.
🧑🎓 Tutorial: Building an LLM App in Python with Vercel's AI SDK
Vercel AI SDK is a toolkit designed to help developers build AI-powered applications with various frameworks. It consists of two main components:
AI SDK Core: A unified API for generating text, structured objects, and building agents with LLMs
AI SDK UI: Framework-agnostic hooks for quickly building chat and generative user interfaces
Vercel’s AI SDK is built primarily as a TypeScript toolkit, which means there isn’t an official Python version available. However, you can still integrate its functionality into a Python project by considering one of the following approaches:
Exposing an API: Create a Node.js microservice using the SDK and call it from Python with HTTP requests.
Direct API Interaction: Replicate the SDK’s web API calls directly in Python using libraries like
requests.Hybrid Approaches: Run a Node.js script via Python’s
subprocessor use IPC (e.g., sockets) to bridge between Python and Node.js.Alternative Python Libraries: Consider native Python options (e.g., Hugging Face Transformers, TensorFlow) for similar AI functionality.
Each of these methods allows you to benefit from Vercel’s AI features while keeping your primary application in Python. The best choice depends on your specific use case, deployment constraints, and how tightly you want to couple your Python and Node.js (or TypeScript) codebases.
The below tutorial demonstrates the Direct API Interaction approach. Instead of relying on a Node.js microservice or bridging via subprocesses, it builds a Python backend (using FastAPI) that implements Vercel's AI SDK’s Data Stream Protocol directly. This lets the Python service stream responses in a format that the Next.js frontend (using Vercel's AI SDK UI) can consume.
Specifically, the tutorial shows how to:
Create a FastAPI backend in Python that formats responses according to Vercel's Data Stream Protocol
Set the required headers (particularly
x-vercel-ai-data-stream: v1) that the Vercel AI SDK expectsStream responses from LLMs (like OpenAI's models) in a format that the Vercel AI SDK can interpret
Build a Next.js frontend that uses the Vercel AI SDK's
useChathook to communicate with the Python backend
First, create a project directory and set up a Python virtual environment:
mkdir vercel-ai-python-app
cd vercel-ai-python-app
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateInstall the necessary Python packages:
pip install fastapi uvicorn openai python-dotenv pydanticConfigure environment variables by creating a .env file:
OPENAI_API_KEY=your_openai_api_key_hereSet up the Next.js frontend:
npx create-next-app@latest frontend --typescript --eslint --tailwind --app
cd frontend
npm install ai @ai-sdk/react @ai-sdk/openaiImplementing the FastAPI Backend
Create a basic FastAPI application that implements the Data Stream Protocol:
import os
import json
from typing import List
from fastapi import FastAPI, Response
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from openai import OpenAI
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Initialize FastAPI app
app = FastAPI()
# Add CORS middleware
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# Initialize OpenAI client
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
# Define request model
class ChatMessage(BaseModel):
role: str
content: str
class Request(BaseModel):
messages: List[ChatMessage]
def stream_data(data: str):
"""Format data according to the Vercel AI SDK Data Stream Protocol."""
return f"0:{data}\n"
@app.post("/api/chat")
async def chat(request: Request):
# Set up streaming response
async def event_generator():
# Convert Pydantic models to dictionaries for OpenAI API
messages = [{"role": msg.role, "content": msg.content} for msg in request.messages]
# Create a streaming completion
stream = client.chat.completions.create(
model="gpt-4o",
messages=messages,
stream=True,
)
# Stream the response chunks
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
yield stream_data(json.dumps(content))
# Return a streaming response
return Response(
content=event_generator(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Encoding": "none",
"x-vercel-ai-data-stream": "v1" # Important header for Vercel AI SDK
}
)
The above code defines input models, streams GPT-4o chat completions, and returns them via a server-sent events endpoint for a Next.js Vercel AI SDK frontend to consume in real-time.
Requesting a Chat Completion
Inside
event_generator(), the code sends the user’s messages to OpenAI’s GPT-based model by callingclient.chat.completions.create(...).Setting
stream=Truetells OpenAI to return partial responses (chunks) instead of waiting for one big final response.
Processing the Stream
As each chunk of text arrives from the OpenAI model (
for chunk in stream:), the code checks if there’s any actual content (chunk.choices[0].delta.content).If there is content, it’s wrapped using the
stream_datafunction. This function formats the text so the frontend knows how to handle it.
Server-Sent Events (SSE)
return Response(..., media_type="text/event-stream", ...)tells the browser or frontend client that this response is an SSE (server-sent events) stream.SSE allows the server to send new pieces of data (in this case, parts of the chatbot’s reply) to the client as soon as they’re generated.
Real-Time Updates in the Frontend
The Next.js Vercel AI SDK listens for these SSE messages. Each chunk of text is displayed right away in the chat window, creating a real-time streaming experience for the user.Creating the Next.js Frontend
Create a simple chat interface using the Vercel AI SDK:
'use client'
import { useChat } from '@ai-sdk/react'
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit, isLoading } = useChat({
api: 'http://localhost:8000/api/chat'
})
return (
<main>
{messages.map((m,i) => <p key={i}>{m.content}</p>)}
<form onSubmit={handleSubmit}>
<input value={input} onChange={handleInputChange} disabled={isLoading} />
<button type="submit" disabled={!input.trim() || isLoading}>Send</button>
</form>
</main>
)
}Running the Application
Start both the backend and frontend servers:
# Terminal 1: Start the FastAPI backend
uvicorn api.main:app --reload --port 8000
# Terminal 2: Start the Next.js frontend
cd frontend
npm run devVisit http://localhost:3000 to see your chat application in action!
Next Steps: To enhance your application, consider:
Adding Tool Functionality: Implement tools for tasks like weather information or web searching
Improving Error Handling: Add robust error handling for a better user experience
Exploring Deployment Options: Deploy your application to platforms like Vercel, Railway, or Fly.io
So overall in the above example, the Data Stream Protocol acts as a bridge between your Python backend and the TypeScript/JavaScript frontend, enabling seamless communication without requiring you to rewrite your backend in TypeScript or Node.js.
The integration of Python's AI ecosystem with Vercel's frontend tooling opens up many possibilities for building sophisticated AI applications. By using the Stream Protocol as a bridge between these technologies, you can create responsive, user-friendly experiences that leverage the best of both worlds.
For more information, visit the Vercel AI SDK Documentation and explore the FastAPI Documentation.
That’s a wrap for today, see you all tomorrow.