


Read time: 3 min 27 seconds
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
Google has launched native image generation in Gemini 2.0 Flash, making the first major model in the industry to ship a fully integrated multimodal AI model.
You can now experiment with this feature completely FREE using the gemini-2.0-flash-exp model via Google AI Studio and the Gemini API.
I honestly can not believe such a beautiful and powerful model is made available for Free by Google.
Remember to choose “Gemini 2.0 Flash Experimental” in Google AI studio.

And you can get the API key from Google AI studio by clicking on this button.

Unlike diffusion models like OpenAI’s DALL·E, Gemini 2.0 Flash generates images natively within the same model, allowing for greater accuracy and interactive editing.
You can remove and add objects, insert text, colorize photos, generate a visual story, and do much more.
Here’s a quick code snippet for image generation and then editing the image with a second prompt.

Explanation of this below part
for piece in gemini_response.candidates[0].content.parts:
if piece.inline_data:
show_generated_image(piece.inline_data.data)
if output_filename is not None:
persist_image(piece.inline_data.data, output_filename)the gemini-2.0-flash-exp model returns a multimodal response object. This response object can contain text parts, image parts, or even other modalities (in more advanced use cases). The library organizes that data in a hierarchical structure, somewhat like this (simplified for illustration):
The gemini_response object structure
When you call Gemini (or any multimodal model in this library), the returned gemini_response is not just a simple string. Instead, it’s an object with multiple nested attributes to handle all the complexity of multimodal output. Specifically:
gemini_response.candidates: A list of possible outputs (candidates) from the model. Sometimes you get more than one candidate if you request multiple completions.gemini_response.candidates[0]: We typically look at the first candidate (index0) for a single-answer scenario.gemini_response.candidates[0].content: This holds the actual content (text, images, etc.) generated or transformed by the model.gemini_response.candidates[0].content.parts: Because the output can be multimodal, the library breaks it down into multiple parts—some may contain text, some may contain images, etc.
Hence, gemini_response.candidates[0].content.parts is a list in which each item is a “part” object.
Checking if a part is an image
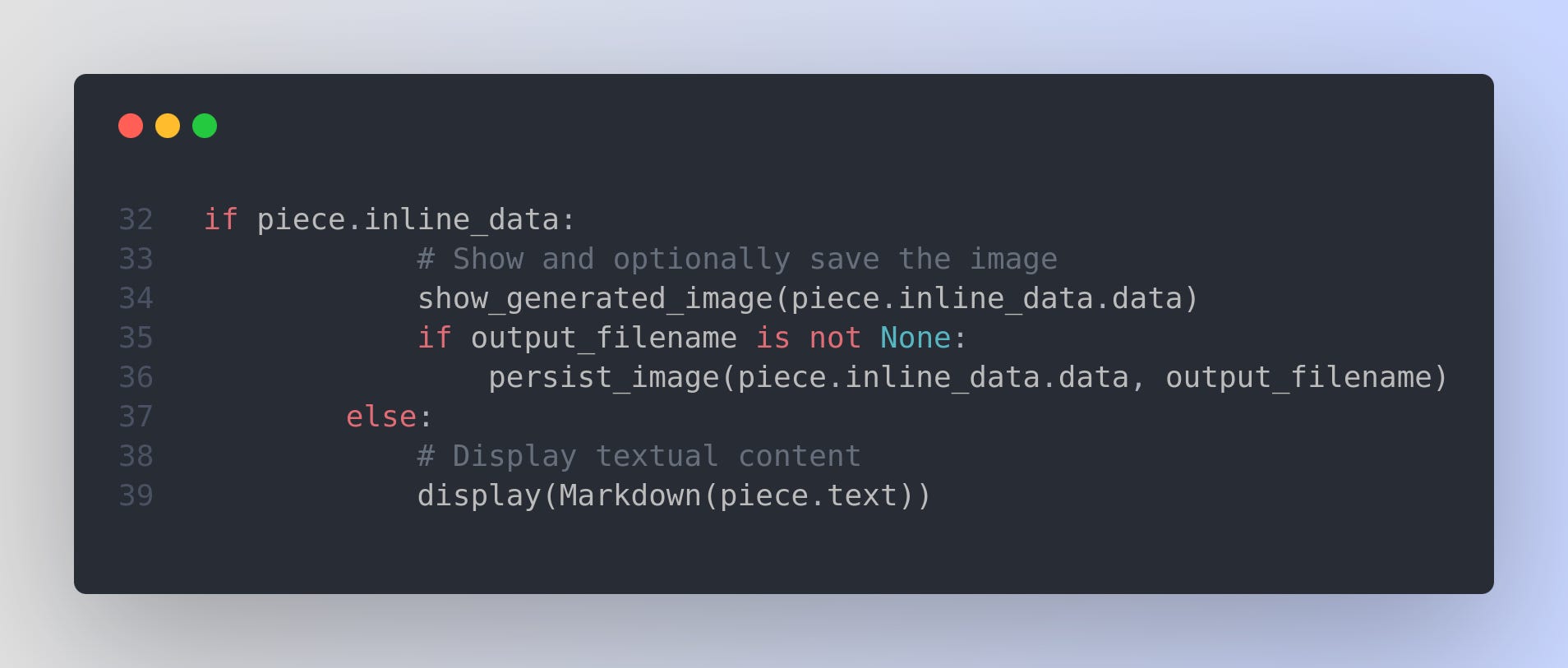
piece.inline_data: A special attribute for binary data (like images) within thatpieceobject. If it’s not None or empty, it indicates that thispieceis an image (specifically, the raw bytes of an image).So, if
inline_datais present, we display the image (show_generated_image) and optionally save it to disk (persist_image).
The code generated this 1st image and then based on my second prompt changed it.

Script to Colorize all the images of a given directory, at once
If a have a lot of old black and white family photos, you can colorize them all at once with this code for free with “Gemini 2.0 Flash Experimental”.
(Please note, maintain responsible time delay so not to overload the Gemini API)

The above code recursively scans a given directory (PARENT_DIR) to find all images (JPG, JPEG, PNG). It then sends each image, two per minute, to the Gemini model (gemini-2.0-flash-exp) with the prompt “colorize this photo.”
If an error occurs for any image, the code skips it and continues to process the rest. After the model returns a colorized version, the code saves the output image in a new subfolder named COLORIZED_WITH_GEMIN within the original image’s folder.
Throughout processing, it prints a dynamically updated, single-line estimate of the remaining time based on how many images are left and a rough per-image duration. This helps the user monitor progress without overloading the API rate limit (two images every 60 seconds).
Thanks for reading, see you next time..