


🥉 Google released Gemma 3: 128k Long-Context Window and multimodal support

Read time: 9 min 27 seconds
📚 Browse past editions here.
( I write daily for my for my AI-pro audience. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-March-2025):
🥉Google released Gemma 3: 128k Long-context window and multimodal support breaks typical LLM limits.
👨🔧 OpenAI launched new Responses API comes with web search, the ability to look through files, and computer use out of the box
🥉 Google released Gemma 3: 128k Long-context window and multimodal support breaks typical LLM limits.
⚡ Overview
Gemma 3 is an open-source Large Language Model with text and vision support. It handles up to 128k tokens in a single sequence, supports over 140 languages, and uses new attention designs to reduce memory overhead. It outperforms many larger proprietary models while fitting on a single H100 GPU.
🏆 Key Capabilities
Supports over 140 languages
Four sizes with 1B, 4B, 12B, 27B are released as pre-trained and instruction-tuned versions.
Rank number-1 in open, non-reasoning model segment in LMArena with a score of 1338, above o1-mini
Gemma 3 12B outperforms Gemma 2 27B, and the same for 4B and 9B
Handles image and video input alongside text
Scores 1338 in LMArena, placing it in the top tiers of open models
Offers 128k context window for long text passages
1B text-only version; 4B, 12B, 27B versions with vision + text
Trained on 14 trillion tokens (for the 27B)
Fits on one H100 for the 27B variant
Uses QK-norm instead of attention softcapping
5:1 ratio of local to global attention layers, each local layer has a 1024-token span
Post-training uses BOND, WARM, WARP reinforcement learning methods for better math, reasoning, and coding
How to use the model
All models are in in Huggingface or Experiment directly in Google AI Studio
And with Huggingface transformers, the easiest way to get started with Gemma 3 is using the pipeline abstraction.
You can combine (“interleave”) text and image inputs within a single conversation. Instead of sending text alone, you can insert images at specific points in the text and treat them as additional inputs for the model to consider.
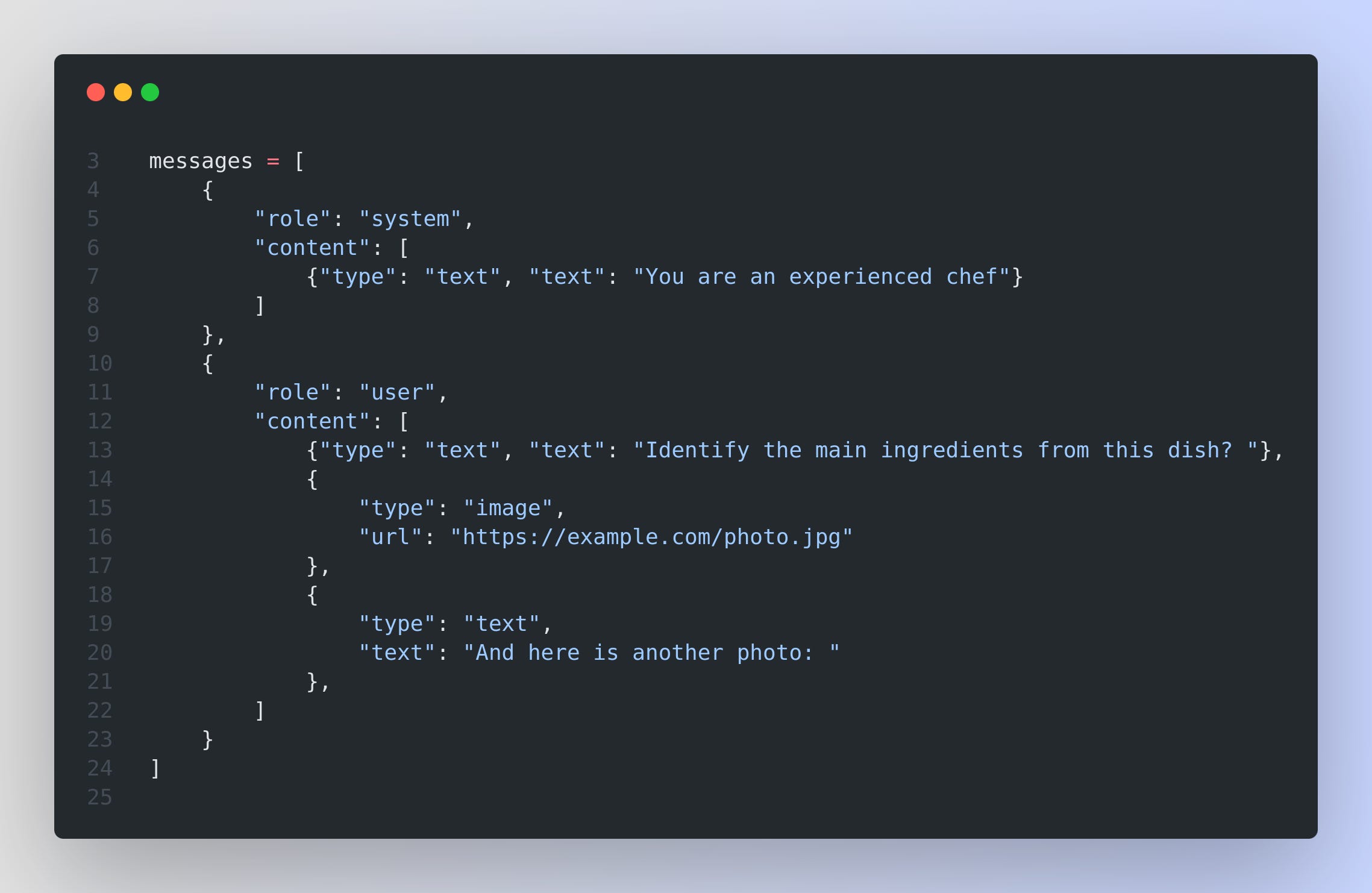
And below is an example of a more detailed inference with the Hugging Face transformers library using Gemma 3
The transformers integration comes with two new model classes:
Gemma3ForConditionalGeneration: For 4B, 12B, and 27B vision language models.
Gemma3ForCausalLM: For the 1B text only model and to load the vision language models like they were language models (omitting the vision tower).
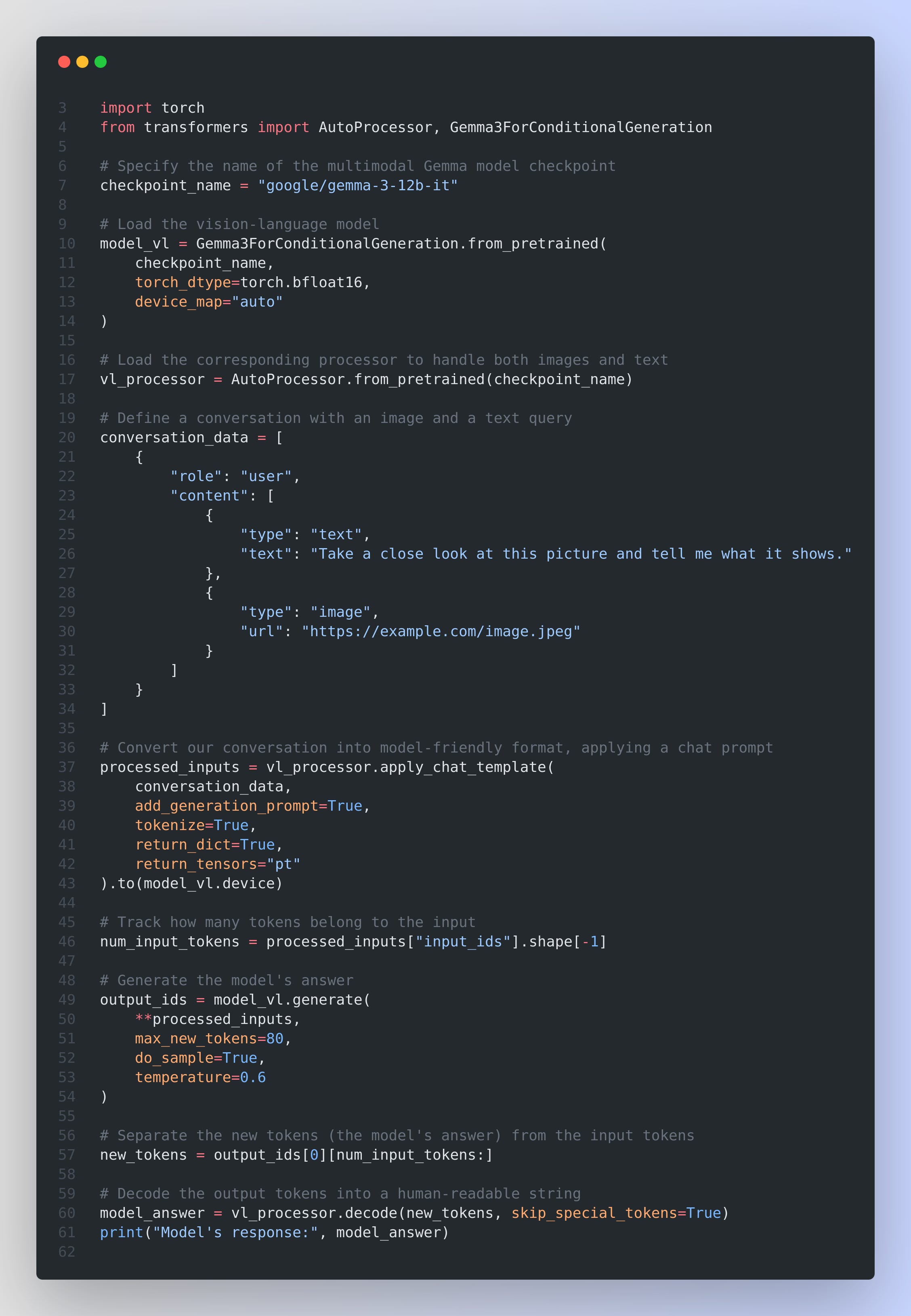
📏 Extended Context Window
Trained at 32k tokens, then RoPE-scaled to 128k. Maintains coherence in tasks needing long documents or large textual inputs. Minimal performance drop even at extreme sequence lengths.
🖼️ Multimodality and Vision
A frozen SigLIP encoder turns images or video frames into compact token embeddings. A Pan & Scan algorithm processes non-square or high-resolution images through efficient windows, letting Gemma 3 handle large, complex visuals.
🚀 Training and Efficiency
Models range from 1B to 27B parameters. Each size is optimized for minimal GPU usage. Distillation from a larger teacher plus RL-based refinements (BOND, WARM, WARP) boosts math, reasoning, and coding abilities.
🤖 Instruction-Tuned Variants
Instruction-tuned models (IT) follow a simple chat format with <start_of_turn> tokens and user/model roles. They produce structured outputs, handle function calls, and respond to image-based questions.
🔩 Architecture Details of Gemma 3 (Local vs Global)

How the 128k token context was made feasible on smaller hardware. Read the Technial Report here.
🏗️ Big Picture of Local vs. Global Layers
Local layers restrict their attention to a fixed window of tokens, say 1024, rather than scanning the entire text input. Global layers can look at the entire sequence. Combining them in a single transformer lets you keep memory low (because local layers store less key-value data) while still preserving broad context via occasional global layers.
🔎 Local Layers at Work
The attention mechanism focuses on a chunk of 1024 tokens.
Each local layer stores the key-value embeddings for those 1024 tokens.
This means the model doesn't keep a massive memory buffer for every token across thousands of positions.
Each local layer is cheaper because it handles only a fraction of the text at once.
At runtime, if your text spans 128k tokens, a local layer won't try to attend to every single token in that range. Instead, it attends to a sliding window around the current token. This drastically lowers memory usage.
🌐 Global Layers for Full Awareness
A global layer attends to the entire context at once.
This provides an overview of everything in the sequence.
It ensures the model can capture long-range links between tokens, far beyond the local window size.
Fewer global layers mean less memory overhead, but they still keep global reasoning intact.
If you only had local layers, the model wouldn’t connect widely separated tokens. If you only had global layers, you’d have huge memory demands. Mixing both in a ratio manages the best of both.
🤖 Why Use a 5:1 Ratio?
5 local layers followed by 1 global layer is a pattern used to cut memory while keeping performance.
Most layers handle small windows (cheap in memory).
A single global layer is interspersed to maintain broader context.
This interplay keeps the model from “forgetting” earlier text or ignoring far-apart words.
If you had more global layers, memory usage would balloon. If you had fewer global layers, the model wouldn’t link distant content as well.
💾 Memory Footprint
KV cache (key-value cache) grows with how many tokens each layer processes. Global layers store key-value embeddings for all tokens, which can be massive at 128k. Local layers only store embeddings for 1024 tokens. Because they dominate the architecture (5 out of every 6 layers), your overall cache size shrinks.
In a global-only design, every token in the entire sequence is stored for each layer. At 128k tokens, that’s enormous. By using mostly local layers, the memory overhead is drastically reduced. The occasional global layer is still expensive, but because there aren’t many of them, the total cost remains manageable.
🧩 Sliding Window Approach
Local layers shift their window forward with the sequence. Each token only sees the nearby 1024 positions. When you move on to the next token, the window slides. This ensures local layers always focus on a small subset of the text, never the entire 128k chunk.
Reduces the chance of memory blowup.
Keeps each local attention head simpler: only 1024 keys and values at a time.
Global layers occasionally unify all the token information so that earlier text can still matter for later tokens.
🔧 Practical Advantages
Much smaller key-value cache usage.
Better performance than purely local or purely global designs.
Makes 128k token context feasible on smaller hardware.
Preserves crucial across-text relationships through those global layers.
🔗 Final Takeaway
Local layers handle small chunks to save memory, while the fewer global layers ensure the model still connects distant ideas. This hybrid approach offers extended context without blowing up hardware requirements.
🌍 Why It Matters
Gemma 3’s extended context, multilingual coverage, and low memory footprint open advanced LLM functionality to broader deployments. The design balances performance with practical hardware constraints.
👨🔧 OpenAI launched new Responses API comes with web search, the ability to look through files, and computer use out of the box
🤖 Overview
OpenAI introduced new tools that simplify building AI agents. They include the Responses API for multi-step tasks, built-in tools for web and file search, and a computer-use interface. There is also an open-source Agents SDK for orchestrating agent workflows, handoffs, guardrails, and observability.
🔧 The Responses API
It streamlines multi-step tasks by combining chat-based text generation with tool calls in a single operation. It is a superset of the Chat Completions API, meaning it can handle everything Chat Completions does plus built-in tools. One call can invoke web search, file lookups, or even system actions.
Developers specify which built-in tools they want (for instance, "web_search", "file_search", or "computer_use"). The model decides when to use these tools during a conversation. It sends a tool request, retrieves the result, and continues all in one conversation loop. This eliminates juggling multiple APIs or external orchestration services.
It automatically tracks each step of the interaction. Developers gain visibility into the entire flow, seeing how and why the AI uses each tool. This structure reduces the prompt complexity needed to guide multi-stage answers. Token usage is billed as usual, and the same safety measures and data handling policies apply.
When a Responses API call completes, the agent returns both the conversation text and any relevant output from its tools, saving time and code. This setup makes it simpler to create agents that gather info from multiple places, combine it, and return a single coherent result. Checkout the Docs here.
🌐 Built-in Tools
Web search provides fresh data from the web with sources included.
File search retrieves relevant documents with metadata filtering and query optimization.
Computer use automates browser or system interactions by translating the agent’s actions into real commands.
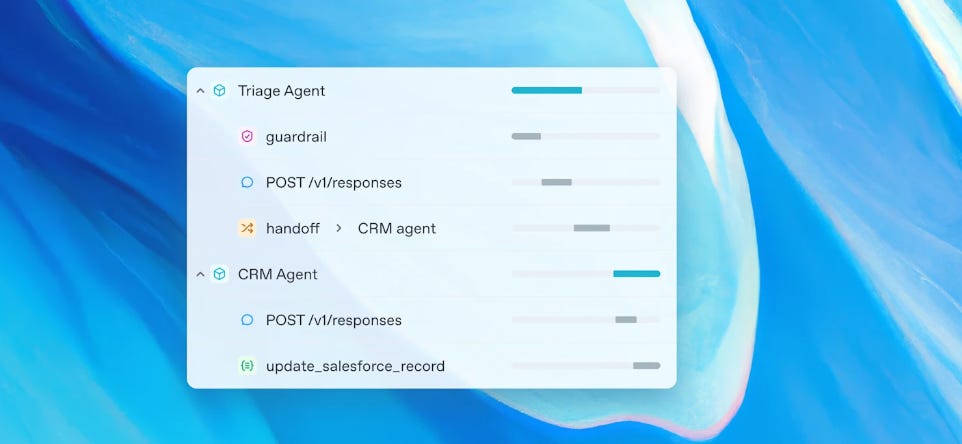
🛠️ Agents SDK
It helps coordinate multiple agents and tools in a single pipeline. It includes:
Agents that manage large language models and tool usage.
Handoffs to pass tasks among different agents.
Guardrails for safety checks and validations.
Tracing & observability to debug and optimize.
📡 Basic Usage (Web Search)

The model automatically calls the web search tool, gathers info, and returns an answer with a citation. This single API call replaces multiple steps in older approaches.
For Migrating from Chat Completions or Assistants checkout this official page.
Key Differences: Chat vs Responses API
Agentic vs. Standalone: Responses includes built-in tools (web search, file search, computer use) for action-based tasks, whereas Chat Completions is more for standard text responses.
Simpler Multi-Step Logic: Responses uses item-based events (e.g., new text or function call), making multi-turn workflows easier. Chat Completions appends to a messages list, so you must track state yourself.
Event-Driven State: Responses handles conversation flow and tool usage in one call, storing metadata by default. Chat Completions doesn’t store conversation context unless you manage it.
Different Request/Response Shapes: Responses replaces
messageswithinputand returns objects describing each output event, while Chat Completions returns achoices[]array.
⚙️ What it means for enterprises
It lets enterprises automate workflows with minimal custom coding. Integrations for web search, file search, and computer use can replace manual tasks in outdated systems. The open-source Agents SDK coordinates these actions, making it simpler to unify data, streamline processes, and maintain oversight with built-in security and observability.
That’s a wrap for today, see you all tomorrow.