
On Task-specific and General-purpose Distillation Techniques to Enhance Reasoning Capabilities of LLMs


Read Time: 31 min.
( I publish this newletter very frequently. Noise-free, actionable, applied-AI developments only).
Chain-of-Thought distillation is a technique that transfers the multi-step reasoning abilities of a large "teacher" language model to a smaller "student" model. In this process, the teacher generates detailed, step-by-step explanations (its chain-of-thought) for solving problems, and the student is trained to mimic this reasoning process, enabling it to tackle complex tasks with fewer parameters.
Table of Contents
Introduction
Key Challenges in CoT Distillation
Distillation Techniques & Strategies
Progressive and Structured Distillation
Leveraging Negative and Diverse Data
Multi-Modal and Mixed-Format Reasoning
Implicit and Hidden-State Reasoning
Adaptive and Partial Reasoning Transfer
Encoder-Only vs Decoder-Only Architectures
Applications Across Domains
Resource and Budget Considerations
Introduction
Chain-of-Thought (CoT) distillation refers to training smaller language models to replicate the step-by-step reasoning behavior of much larger models. Large Language Models (LLMs) like GPT-4 can tackle complex problems by generating intermediate reasoning steps, but doing so greatly increases inference cost (many “reasoning tokens”) (Notes on OpenAI’s new o1 chain-of-thought models). CoT distillation aims to compress these multi-step reasoning abilities into Small Language Models (SLMs) (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning). This would combine the interpretability and problem-solving power of CoT with the efficiency of a smaller architecture. Recent research (2024–2025) has focused on discovering effective distillation methods so that a student model can “think step-by-step” and achieve strong reasoning performance while using a fraction of the parameters and computational resources.
Both decoder-only LLMs (generative models) and encoder-only models (e.g. BERT-like classifiers) are being taught to perform multi-step reasoning via CoT distillation. Below, we review the latest techniques, insights from research papers on arXiv, and industry perspectives on shrinking reasoning models without losing their chain-of-thought competence.
Key Challenges in CoT Distillation

Transferring reasoning is not as simple as copying answers; it involves teaching the process. Several key challenges have been identified in recent studies:
Selecting the Right Teacher: Surprisingly, the highest-accuracy teacher model is not always the best for distillation. If a teacher’s solutions are too complex or lack diversity, the student may learn less. For example, Chen et al. (2025) found that diverse and complex reasoning supervision can outweigh raw teacher accuracy, and an overly strong teacher might overshoot the student’s capacity (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning). The student’s optimal learning occurs when the teacher’s CoT is well-matched to the student’s abilities (neither too advanced nor too simplistic).
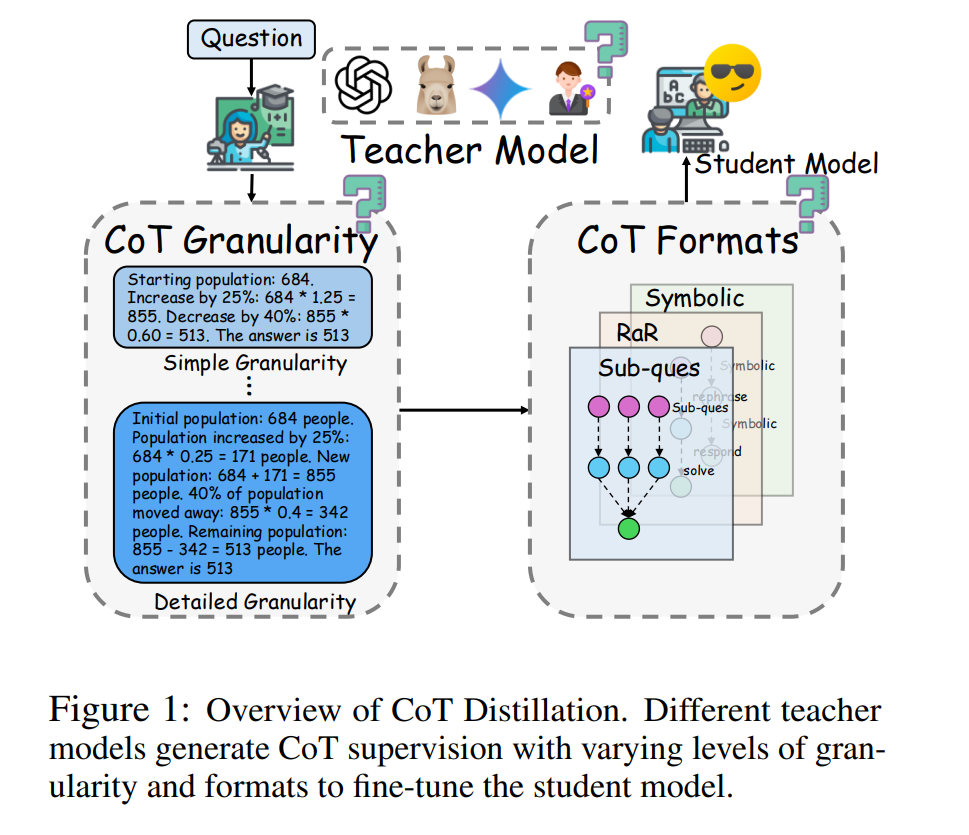
Reasoning Granularity: How detailed should the taught chain-of-thought be? Fine-grained, step-by-step rationales can help stronger students, but may overwhelm weaker ones. A comprehensive 2025 study observed a non-monotonic effect: a 2B student model benefited from very detailed reasoning steps, whereas a much smaller model did better when trained on simpler, higher-level reasoning traces (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning). Too many steps can confuse a tiny model, indicating an optimal granularity level exists for each size.
Format of Reasoning: The format or style of the chain-of-thought (formal logic, natural language, structured lists, etc.) influences learning. Large LLMs show sensitivity to CoT format, but small models rely more on fine-tuning and are less sensitive to format differences. This suggests that as long as the student sees some logically organized rationale, the exact wording or style (e.g. bullet list vs prose) is not critical – an encouraging sign that knowledge transfers across formats.
Errors and Correctness: Big teachers sometimes produce flawed reasoning or incorrect answers, especially on hard problems. A naïve approach would discard these “failed” samples, but recent work shows value in negative data. Li et al. (2024) demonstrated that including chains ending in wrong answers can teach the student what not to do, improving robustness ([2312.12832] Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data).
Likewise, another study observed that a student can learn reasoning patterns even from incorrect intermediate steps – as long as the overall structure of thinking is intact (LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!). In short, imperfect reasoning is still informative.
Overfitting vs Generalization: A major issue is that small models tend to memorize the teacher’s demonstrations rather than truly generalize the reasoning skill (Enhancing Generalization in Chain of Thought Reasoning for Smaller Models). They might perform well on the training-format problems but falter on novel ones. Yin et al. (2025) showed that standard CoT distillation often yields an over-confident but narrow model, and propose methods to push the student from rote memorization toward more robust reasoning (discussed later) (Enhancing Generalization in Chain of Thought Reasoning for Smaller Models).
Preserving generalizable “reasoning principles” in a compression process is non-trivial.
Inference Cost Trade-offs: One motivation for CoT distillation is runtime efficiency. OpenAI’s o1 models, for instance, use long hidden reasoning sequences (“reasoning tokens”) internally, which improves reasoning but can be slow (Notes on OpenAI’s new o1 chain-of-thought models). Distilled models seek to maintain accuracy with fewer reasoning steps or faster execution. A challenge is achieving this without losing the advantages of deep reasoning – often requiring creative training schemes so the student can reason implicitly or more efficiently than the teacher.


These challenges set the stage for various techniques designed to optimize the distillation of reasoning. Next, we delve into the approaches researchers have developed to address these and effectively compress multi-step thought processes into smaller models.
Distillation Techniques & Strategies
Progressive and Structured Distillation
One class of methods treats reasoning distillation as a curriculum learning problem – gradually teaching the student more complex reasoning steps. Keypoint-Based Progressive Distillation (KPOD) is a prime example ([2405.16064] Keypoint-based Progressive Chain-of-Thought Distillation for LLMs).

It addresses two issues: (i) not all tokens in a rationale are equally important for the final answer, and (ii) a student shouldn’t learn all steps at once. KPOD introduces a token weighting module to highlight key informational tokens in the teacher’s chain-of-thought so that crucial steps get more attention during training ([2405.16064] Keypoint-based Progressive Chain-of-Thought Distillation for LLMs). Furthermore, it trains the student in stages: first learn to generate the final few steps of the solution, then progressively include earlier steps. This in-rationale progression mirrors human learning (start with the conclusion, then fill in the reasoning backwards) and prevents the student from being overwhelmed initially. Empirically, KPOD achieved large gains on reasoning benchmarks by focusing the student on core reasoning “checkpoints” and then extending the horizon.
For very long reasoning chains, Luo et al. (2025) propose structuring the distillation data itself. Their framework, DLCoT (Deconstructing Long CoT), breaks complex multi-hop solutions into segments and optimizes each part ([2503.16385] Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation). They first segment a lengthy chain-of-thought into smaller logical chunks, filter out any unsolvable or redundant segments, and then train the student with an emphasis on correctly handling intermediate states and errors . This structured approach boosted student performance on tasks requiring 10+ reasoning steps, improving both accuracy and token-efficiency (fewer useless tokens). The key idea is to teach long reasoning in pieces – ensuring the student grasps each link of the chain instead of being exposed to an unmanageable long sequence.
Notably, experiments confirm that finer granularity is not always better for every student. Chen et al. (2025) varied the reasoning detail from very coarse to very fine and found that a stronger student model prefers more detailed CoT, while a weaker student actually became less accurate with overly detailed rationales (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning). This non-monotonic trend suggests using a matching strategy: small students might start with high-level reasoning distillation and gradually move to granular CoT as they scale or improve. In practice, progressive schemes (like KPOD’s final-step-first training) embody this principle by easing the student into the full reasoning.
Leveraging Negative and Diverse Data
Traditional distillation might throw out teacher answers that are wrong. New research instead turns these into a feature. Li et al. (2024) introduced a “turning dust into gold” approach where negative examples (teacher’s incorrect reasoning paths) are deliberately included during training ([2312.12832] Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data). The student model is optimized not only to imitate correct chains but also to recognize and avoid patterns leading to wrong answers . Concretely, their framework adds a stage where the student practices on wrong-answer chains and learns to identify the mistake, essentially learning from the teacher’s failures. This yielded better arithmetic reasoning accuracy than using only flawless solutions. The insight is that incorporating a diverse set of outcomes (both success and failure) provides a richer supervisory signal – similar to how people learn from errors.
Diversity of reasoning is also harnessed in mixed-distillation methods. Instead of one “best” chain-of-thought per problem, the student is trained on multiple reasoning paths. Recent work on Mixed Distillation (MD) generated a variety of CoT explanations for each query and created a well-balanced training set of different reasoning styles (here).

They combined this with a novel multi-task loss so the student can adaptively switch reasoning modes. In particular, Li et al. (2024) merged Chain-of-Thought (natural language) with Program-of-Thought (code) solutions in one student model (here). The model sometimes reasons in plain language, other times writes a short Python snippet to compute the answer – whichever is effective. This “mixed thought” training dramatically improved math word problem solving; a single 7B student (Mistral-7B) distilled with both CoT and code reasoning outperformed its GPT-3.5 teacher on several benchmarks (e.g. +87.5% on SVAMP math, surpassing the teacher) (here). By seeing diverse reasoning formats, the student became more flexible at inference time, activating the right tool (chain-of-thought or program execution) per problem. This underscores the benefit of covering different reasoning strategies during distillation.
Another form of diversity is simply sampling variations of CoT. Rather than one deterministic chain per question, techniques akin to symbolic knowledge distillation (as in earlier 2023 works) sample many plausible chains from the teacher and train the student on all of them (Symbolic Chain-of-Thought Distillation: Small Models Can Also “Think” Step-by-Step). Recent experiments reinforce that sampling multiple reasoning paths is crucial for small models to truly internalize a reasoning skill. It exposes the student to slight rephrasings, alternative solution paths, and edge cases, preventing brittle learning. In sum, feeding a breadth of reasoning examples – including incorrect and varied ones – acts as data augmentation for thought processes, yielding a student that is both accurate and less likely to be confused by novel inputs.
Multi-Modal and Mixed-Format Reasoning
While most CoT distillation research focuses on text-based reasoning, the ideas extend to other data modalities and formats of reasoning. A noteworthy direction is applying CoT distillation in multi-modal systems. Shi et al. (2025) introduced Agent-of-Thoughts Distillation (AoTD) for a Video-LLM that answers questions about videos ([2412.01694] Enhancing Video-LLM Reasoning via Agent-of-Thoughts Distillation).

In Video Question Answering, reasoning might involve tracking events over time and space. AoTD uses an agent-based teacher that breaks a video question into sub-questions (e.g. “what color was the car?” then “where did it go?”) and solves each with specialist models (vision models, etc.). The intermediate results form a reasoning chain (with e.g. visual observations as steps). By instructing a student video-LLM on these generated chains, they achieved better grounded reasoning – the distilled model can explain its answer from the video evidence step-by-step, leading to improved accuracy on multi-choice and open-ended video QA. This showcases CoT distillation beyond pure text: even for complex perception tasks, breaking a problem into steps and distilling that process helps a smaller model learn to reason through the subtasks.
Another example of mixed-format reasoning is the integration of symbolic or tabular reasoning into the distillation pipeline. Fan et al. (2024) tackled scientific table-to-text generation by having a teacher LLM generate an explanation of how to read the table (the CoT) along with the final description (Effective Distillation of Table-based Reasoning Ability from LLMs). They call this a two-stage distillation: first use an LLM to produce a textual reasoning trace that identifies which rows/columns are relevant and what math to do, then fine-tune a smaller model (T5) on this augmented data. The result was dramatic – a 220M parameter model distilled with these table reasoning steps outperformed a 175B teacher on some metrics of the SciGen table task. This indicates that for specialized domains (tables, code, etc.), injecting structured reasoning knowledge (like how to aggregate table cells stepwise) into a compact model is highly effective. It enables domain-specific reasoning without needing a giant model at runtime.
We also see programmatic reasoning being distilled: models like PoT (program-of-thought) can execute code internally. By training students on the traces of code execution from a larger model, even 7B models learned to use Python as a tool for reasoning (here). In effect, the student acquires a built-in scratchpad to do arithmetic or logical computations. Mixed CoT/PoT training ensures the student doesn’t treat reasoning as only one modality. This multi-format learning is expanding the scope of CoT distillation – it’s not just “think in words,” but think in whatever form is most efficient (words, code, structured plan) and produce the final answer.
Implicit and Hidden-State Reasoning
A cutting-edge line of work asks: Does the reasoning have to be explicit? Perhaps not – a student model could carry out multi-step reasoning internally without verbosely writing it out. Deng et al. (2024) explore this with Implicit CoT via Knowledge Distillation (Implicit Chain of Thought Reasoning via Knowledge Distillation | OpenReview).

They train a student model to perform reasoning in its hidden layers instead of output tokens. A powerful teacher is first fine-tuned to produce explicit CoTs for a task (say, multi-digit addition with all steps shown). Then the student is trained such that its intermediate layer activations correspond to the teacher’s step-by-step thinking, even though the student never outputs those steps in text (Implicit Chain of Thought Reasoning via Knowledge Distillation | OpenReview). The student is only responsible for outputting the final answer, but the heavy lifting happens in the latent space (“vertical” reasoning among layers rather than “horizontal” reasoning across time steps). This approach yielded significantly higher math accuracy than a student trained to predict the answer directly. Essentially, the student learns to think silently. The distillation objective aligns the student’s hidden state transitions with the teacher’s chain-of-thought, compressing the reasoning into the network weights. This implicit reasoning is appealing for deployment: it avoids generating long verbose outputs while still doing the multi-step logic internally.
Industry models mirror this idea: OpenAI’s o1 model family, for instance, introduced the concept of “reasoning tokens” which are not emitted to the user but are generated internally during inference (Notes on OpenAI’s new o1 chain-of-thought models). These hidden tokens reflect the model’s chain-of-thought that is pruned from the final answer. From a distillation perspective, one could imagine training a smaller model to produce such hidden reasoning tokens (or equivalent activations) without needing to output them. The Implicit CoT study provides a blueprint for that: it demonstrates a way to distill the process without the prose.
Another benefit of implicit reasoning is speed – generating and parsing long text chains can be slow, whereas internal tensor computations are faster. The implicit approach showed that we can retain CoT benefits (like better accuracy on multi-step problems) without incurring the full token-generation cost. For tasks where rationale verbosity is not needed for the end-user, this is a big win. It is a form of compression that goes beyond parameter count, compressing the communication of reasoning into internal signals.
Adaptive and Partial Reasoning Transfer
Not all problems require a lengthy chain-of-thought – sometimes a direct answer is enough. An interesting distillation idea is to give the student the ability to decide when to think vs when to answer directly. Chen et al. (2024) proposed an adaptive-thinking student that can do either “pre-thinking” (generate rationale then answer) or “post-thinking” (answer first, explain later) ([2404.09170] Distilling Reasoning Ability from Large Language Models with Adaptive Thinking).

They found that always forcing a small model to explain before answering made it fragile: any small error in the long rationale would derail the final answer. By contrast, if the model outputs an answer first and then a rationale, the answer isn’t influenced by rationale mistakes. However, only doing answer-first could degrade the model’s ability to reason on truly hard questions (since it might skip decomposition). To get the best of both, they introduced a plug-and-play mechanism that lets the student adaptively choose whether to produce a chain-of-thought for a given query. A small controller (learned via soft prompts) “perceives” question complexity and decides to trigger CoT mode for hard questions, or just answer directly for easy ones. This adaptive approach improved overall robustness: the student doesn’t waste time explaining trivial queries (faster inference) and avoids unneeded exposure to potential reasoning errors, but still employs full reasoning on the tough cases ([2404.09170] Distilling Reasoning Ability from Large Language Models with Adaptive Thinking). It essentially distilled not just the reasoning skill, but the skill of knowing when to reason.
Another partial-transfer strategy is to distill only a specific part of the reasoning process rather than the whole pipeline. Luo et al. (2024) investigated this in a “Divide-and-Conquer” fashion: they split complex QA tasks into question decomposition and answer synthesis (here). They then only distill the decomposition capability into a smaller model, leaving the actual final solving to either a larger model or another system (here). The rationale is that breaking a problem into subproblems is a more general skill (less tied to world knowledge), so even a cheap model can handle it. Their student (e.g. a 7B Vicuna) was trained to take a question and output a series of sub-questions – learned from GPT-3.5 teacher’s decompositions (here). The evaluation showed the student could generate high-quality breakdowns of questions, which could then be fed to a solver, achieving almost the same performance as the teacher doing everything (here). Meanwhile, if they tried distilling the solving step instead, the student failed to generalize answers well (here). This highlights that not all reasoning sub-tasks are equal – some (like planning the solution approach) compress much better into small models than others (like computing the final answer which may require large knowledge capacity). Such partial distillation offers a practical compromise: use a small model for the “chain-of-thought orchestration” and perhaps call a larger model or external tool to execute the sub-tasks. It’s a modular way to reduce cost: the expensive LLM is only used when needed for sub-questions, with the cheap model directing it.
In summary, adaptive and partial techniques make CoT distillation more efficient and tailored. Adaptive students learn when to think (avoiding unnecessary reasoning), and targeted distillation chooses what to distill (focusing on the reasoning components that a smaller model can master). These innovations ensure that we’re not forcing small models to do more than necessary, which in turn leads to better performance-per-compute.
Encoder-Only vs Decoder-Only Architectures
CoT distillation has been applied primarily to decoder-style models (which generate solutions), but encoder-only models can also benefit from distilled reasoning in appropriate ways. Decoder-only models (like smaller GPT-style or LLaMA derivatives) naturally output a chain-of-thought as text, so most techniques above directly apply. For instance, a 7B decoder model can be fine-tuned to produce a step-by-step explanation followed by the answer, imitating a 70B teacher. Many public distillations follow this recipe – e.g. distilled versions of DeepSeek-R1 reasoning model (open-sourced at 1.5B, 7B, etc.) simply train the decoder to emit the teacher’s full reasoning and answer for each query (here). These students show strong performance on math, coding, and commonsense tasks, validating that decoder architectures can learn complex reasoning behavior when guided appropriately (here).
Encoder-only models, like BERT-style classifiers, don’t generate free-form text, so the chain-of-thought has to be incorporated differently. One approach is rationale supervision: have the encoder predict not just an answer but also whether a reasoning step is valid. For example, in an e-commerce search relevance task, an encoder can be distilled to use rationale embeddings indicating why a result is relevant ([PDF] Rationale-Guided Distillation for E-Commerce Relevance ...). More generally, an encoder can be taught via multi-output training where it produces a label and some intermediate reasoning labels (or it’s paired with a small decoder head to generate an explanation). A recent practical example is using a powerful reasoner to generate synthetic labels for a classification task that requires reasoning, and then fine-tuning a BERT-like model on this data (Distiling DeepSeek reasoning to ModernBERT classifiers – Daniel van Strien). Van Strien (2025) describes leveraging DeepSeek-R1 (a strong CoT model) to label a corpus of scientific papers as to whether they introduce a new dataset. The teacher’s chain-of-thought ensures the labels are accurate (since it “thought through” each decision), and the student ModernBERT is then trained on these high-quality labels. The outcome is an encoder model that performs a task requiring implicit reasoning (spotting dataset introductions) with high accuracy, despite never generating a chain-of-thought itself. Here the CoT was used in data preparation rather than in the model’s output format.
In summary, decoder models tend to internalize and reproduce the chain-of-thought directly, whereas encoder models might embed the distilled reasoning in their weights or use it in an intermediate representation. Encoders can still learn multi-hop logic (as evidenced by improved logical reasoning in distilled BERTs) (RDBE: Reasoning Distillation-Based Evaluation Enhances ... - arXiv), but the evaluation is usually based on their final predictions or scores, not a visible rationale. When a task benefits from reasoning, one strategy is to convert it into a generation task so that an encoder-decoder model (like T5) can be distilled with CoT and then possibly converted back or used as is. Indeed, T5 models fine-tuned on CoT-augmented data (like T5-CoT in table reasoning) significantly outperform those trained on direct input-output pairs (Effective Distillation of Table-based Reasoning Ability from LLMs), showing that even models with an encoder component thrive with CoT supervision.
Overall, decoder-only students are the default for CoT distillation due to their generative nature, but with careful design, encoder-only students can also gain reasoning skills by learning from the outcomes of a teacher’s chain-of-thought (or through joint training with a generator). The choice often comes down to the application: if you need the model to explain its answers, a decoder (or encoder-decoder) is necessary; if you just need better decisions, an encoder distilled on reasoned examples may suffice.
Applications Across Domains
The distilled chain-of-thought paradigm is unlocking advanced applications across numerous domains, by delivering reasoning-on-a-budget:
Mathematics and STEM: This is a flagship domain for CoT techniques. Distilled models like Skyline (Sky-T1-32B student) and others have shown huge leaps in math competition problems (LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!). A distilled 32B model achieved 94% on MATH, nearly matching GPT-4-level performance (here) – a remarkable feat given it was trained from a reasoning-oriented teacher. Even at 7B, students can solve complex grade-school math: Mistral-7B distilled via mixed CoT/PoT was able to handle diverse arithmetic and algebra problems that normally stump baseline 7B models (here). For industry, this means smaller models can power math tutors or scientific calculators that show their work, suitable for educational tech or engineering assistants.
Coding and Debugging: Multi-step reasoning is analogous to planning and debugging in code. Distilled reasoning models have demonstrated strong coding abilities (solving Codeforces puzzles, etc.) by learning thought processes like stepwise pseudocode and self-checking (here). The DeepSeek-R1 distilled family, for instance, includes a 14B model that surpassed a 32B original model on coding challenge benchmarks (here). This paves the way for lightweight AI pair programmers that not only write code but also reason about algorithmic correctness. Startups are exploring 7–13B coders distilled from GPT-4, which could run locally for secure coding assistance with chain-of-thought explanations for each code segment.
Commonsense and Analytical QA: Smaller models often struggle with tricky commonsense questions or analytical reading comprehension. CoT distillation is bridging that gap. For instance, SCoTD (Symbolic CoT Distillation) boosted 1.3B models on CommonsenseQA and StrategyQA by training on GPT-3’s rationales (Symbolic Chain-of-Thought Distillation: Small Models Can Also “Think” Step-by-Step). These students even produced explanations that humans judged as comparable to the 175B teacher’s in quality. This means a 1.3B model can now perform complex commonsense reasoning tasks with credible justifications – valuable for virtual assistants, customer support bots, or any AI that needs to make and explain decisions in open-world scenarios.
Multi-modal Reasoning (Vision + Language): As noted, Agent-of-Thoughts distillation has improved video question answering ([2412.01694] Enhancing Video-LLM Reasoning via Agent-of-Thoughts Distillation). We can imagine similar techniques applied to medical imaging (e.g. a distilled model that explains a diagnosis step-by-step from an X-ray) or robotics (where a small policy model distilled from a larger planner could verbalize its plan before acting). By incorporating CoT, even edge-deployed models (like on a robot or AR device) could carry out reasoning-heavy tasks with limited compute, because the heavy reasoning logic was pre-learned from a bigger model. This cross-modal CoT idea is in early stages, but results so far indicate it can enhance grounding (aligning reasoning with visual evidence) in smaller vision-language models.
Business Logic and Data Analysis: Many enterprise use-cases involve reasoning with structured data – e.g. drawing conclusions from charts, financial reports or inventory tables. The table reasoning distillation work mentioned earlier is directly applicable here. A distilled T5 model that learned to reason over spreadsheets can be integrated into business intelligence tools, giving explanations for its outputs (why it flagged a trend or anomaly) which is crucial for trust. Because the student is small (hundreds of millions of parameters), it could even run on-premises for a company, avoiding sending sensitive data to a massive cloud API. We’re also seeing interest in using distilled CoT models for data cleaning and validation – the model can explain inconsistencies it finds in a dataset by reasoning through the entries, something a raw classifier couldn’t do.
Education and Training: Smaller CoT-capable models are ideal for personalized education, where running a huge model per student is infeasible. A 7B model fine-tuned to provide step-by-step explanations in response to student questions (and perhaps distilled from an expert teacher like GPT-4) can act as a always-available tutor. Because it’s distilled, it can run on a school’s local server or even high-end tablets, ensuring accessibility. Its chain-of-thought gives transparency – a student can see how the AI arrived at an answer in math, logic, or even a humanities question, fostering better learning. Early experiments with such models show they can adapt solutions to a student’s level by controlling rationale granularity (thanks to how they were distilled on varied explanation lengths) (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning).
These examples underscore that almost any domain requiring reasoning can leverage CoT-distilled models. The common theme is interpretable problem solving at lower cost: whether it’s law (an AI explaining a legal reasoning on cases) or finance (an AI analyzing a portfolio with stepwise logic), distillation makes it feasible to deploy these capabilities widely. We already see open-source distilled models being fine-tuned to domain-specific data – e.g. a medical Q&A model distilled from ChatGPT then refined on medical exams. The result is a smaller model that can show its reasoning on medical questions and potentially be used as a clinician’s assistant, all under local governance.
Resource and Budget Considerations
CoT distillation is also attractive from a cost perspective, and strategies diverge for startups versus large enterprises:
For Startups / Low-Resource Teams: The emphasis is on leveraging existing big models to bootstrap a smaller one. It’s often cheaper to use a few hundred API calls or an open large model to generate a distilled training set, than to train a big model from scratch. As an example, Hsieh et al. (Google Research, 2023) showed that a 770M model fine-tuned on a small amount of rationale-augmented data beat a 540B model on certain benchmarks ([2305.02301] Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes). This “performance boost with less data and smaller size” is exactly what a cash-strapped team needs. Practically, a startup can take an off-the-shelf 7B model (like LLaMA-2 7B or Mistral 7B) and use a service like OpenAI or Anthropic to produce, say, 50k reasoning examples for their domain. Using frameworks like HuggingFace’s Transformers or PyTorch Lightning, they can fine-tune the 7B on this synthetic CoT data with modest GPU resources. The Predibase team compiled best practices for such distillations, highlighting tips like include explanation traces from the teacher to boost performance (Graduate from OpenAI to Open-Source: 12 best practices for distilling smaller language models from GPT - Predibase - Predibase) and filter for high-quality rationales to avoid noise . Startups should also consider parameter-efficient finetuning (e.g. LoRA adapters) to train on reasoning data with lower memory footprint. This approach was used in the SkyPilot project, where LoRA on 32B models with just 17k CoT examples yielded huge gains in math reasoning (LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!)– meaning even a single GPU can fine-tune a model for reasoning if the dataset is carefully distilled.
For Large Enterprises: Big players like OpenAI, Google, Meta and DeepMind can afford to experiment with reinforcement learning, massive ensemble teachers, and multi-stage distillation pipelines. OpenAI’s o1 series, for instance, used extensive RL to teach a base model to “think” and then likely distilled that into more efficient variants (the o1-mini model suggests a distilled or compressed version for faster use) (Notes on OpenAI’s new o1 chain-of-thought models). Enterprises can run hundreds of thousands of problem queries through GPT-4 or their latest 100B+ model to build a diverse CoT training corpus – something a small lab cannot. They also deploy specialist models: e.g. use a code solver like AlphaCode as part of generating CoT data for math problems (mixing modalities, as in Mixed Distillation).
The DeepSeek-R1 pipeline exemplifies a heavyweight approach: first train a large model with pure RL to self-improve its reasoning, then do a second-stage supervised distill to various sizes (here). The result was an array of distilled models from 70B down to 1.5B that they released (here). Such multi-stage pipelines are compute-intensive (essentially train big model, then use it to train many small), but yield an entire suite of models for different budget levels. A big tech company can justify this if it needs grade-A reasoning in a consumer device (where only a small model can run) or to offer tiered API services (basic reasoning model vs advanced, etc.).
Open Source Community: Interestingly, CoT distillation research benefits greatly from open models. Many papers used open LLMs (LLaMA, Pythia, etc.) as students and sometimes as teachers. This means the community can reproduce and build upon results without needing secret models. The distillation recipes from 2024 are being shared: for example, code and data from Unveiling Key Factors of CoT Distillation are open-sourced (Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning), and Predibase’s LLM Distillation Playbook consolidates tricks from academia and industry into reusable code (Graduate from OpenAI to Open-Source: 12 best practices for distilling smaller language models from GPT - Predibase - Predibase). So, a resource-conscious team today might not even need to generate all data themselves – they can draw from publicly released distilled datasets (like reasoning traces for GSM8K, AQuA, CommonsenseQA, etc. produced by prior works). This lowers the entry barrier to CoT distillation significantly.
Inference Budget and Deployment: Running a distilled model is far cheaper than using the original LLM. For example, OpenAI’s documentation notes that o1 models may take several minutes for deep reasoning on a single query (Notes on OpenAI’s new o1 chain-of-thought models) which is impractical for real-time use. A well-distilled 13B model might solve the same query in a few seconds with only a slight drop in accuracy – a good trade-off for many applications. Companies can also deploy these models on more accessible hardware (GPUs with 16 GB memory can host a 13B model with 4-bit quantization, and 7B models can even run on high-end CPUs). Quantization and pruning further reduce memory, and since the student has learned to be efficient in its thinking, it may not need as many generating steps as the teacher did. The result is that features like chain-of-thought, which used to be luxury due to expense, become feasible in production even under tight latency or cost constraints.
Maintaining Quality: One must budget for evaluation and iteration. Distilling reasoning is part art, and one may need to iterate on prompts or dataset curation. Techniques like using GPT-4 to judge the quality of generated rationales (Graduate from OpenAI to Open-Source: 12 best practices for distilling smaller language models from GPT - Predibase - Predibase) or filtering out lowest-quality teacher outputs can improve the final student. These extra steps incur some compute cost but pay off in a more reliable model (preventing a waste of a fine-tuning run on noisy data). Startups often budget a few experiments to get distillation right, whereas large orgs automate this with large-scale hyperparameter searches.
In conclusion, chain-of-thought distillation is proving to be a cost-effective strategy to achieve advanced reasoning in small models. By carefully choosing teachers, data, and training schemes, even a tiny fraction of a trillion-parameter model’s compute can yield a model that solves complex tasks and explains itself. This democratizes multi-step reasoning AI – enabling wider use from lean startups to on-device AI, while enterprises push the frontier with even more sophisticated distillation (e.g. distilling multiple skills into one model, or combining reasoning with other abilities like tool use). As research continues into 2025, we can expect even better techniques (perhaps stronger theoretical guarantees on what knowledge distillation preserves, or automated curricula for reasoning). But already, the progress is clear: powerful reasoning is no longer the exclusive domain of giant LLMs – it can be distilled and compressed into fast, nimble models ready to deploy.