


Recent Advancements in Distillation Techniques for Creating Smart but Smaller Models
A comprehensive analysis of recent advancements in distillation techniques, focusing specifically on developments from 2024-2025

Read time: 27 min 35 seconds
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
Table of Contents
Introduction
Fundamentals of Model Distillation
Core Concepts and Terminology
Evolution of Distillation Techniques
Recent Research Breakthroughs (2024-2025)
Representational Approaches to Distillation
Quantification Methods for LLM Distillation
Branch-Merge Distillation
Domain-Specific Distillation for Speculative Decoding
Distillation in Digital Pathology
Technical Implementation Frameworks
PyTorch Implementation Approaches
TensorFlow Implementation Approaches
Framework-Agnostic Techniques
Industry Applications
Cost Considerations and Resource Optimization
Challenges and Limitations
Future Directions
Code implementations: Distilling Llama3.1 8B into Llama3.2 1B using Knowledge Distillation
Introduction
Model distillation has emerged as a critical technique in the AI landscape, addressing the growing tension between model capability and computational efficiency. As foundation models continue to expand in size and complexity, the need for methods that can preserve their performance while reducing their footprint has become increasingly important.
The concept of knowledge distillation, first formalized by Geoffrey Hinton in 2015, has evolved significantly in recent years. What began as a simple teacher-student paradigm has transformed into a sophisticated set of methodologies that enable the creation of smaller, faster models that retain much of the knowledge and capabilities of their larger counterparts

In 2024-2025, we've witnessed remarkable advancements in distillation techniques, with researchers and industry practitioners developing novel approaches that push the boundaries of what's possible with compact models. These innovations have made distillation not just a theoretical concept but a practical solution deployed across various domains and applications.
Fundamentals of Model Distillation
Core Concepts and Terminology
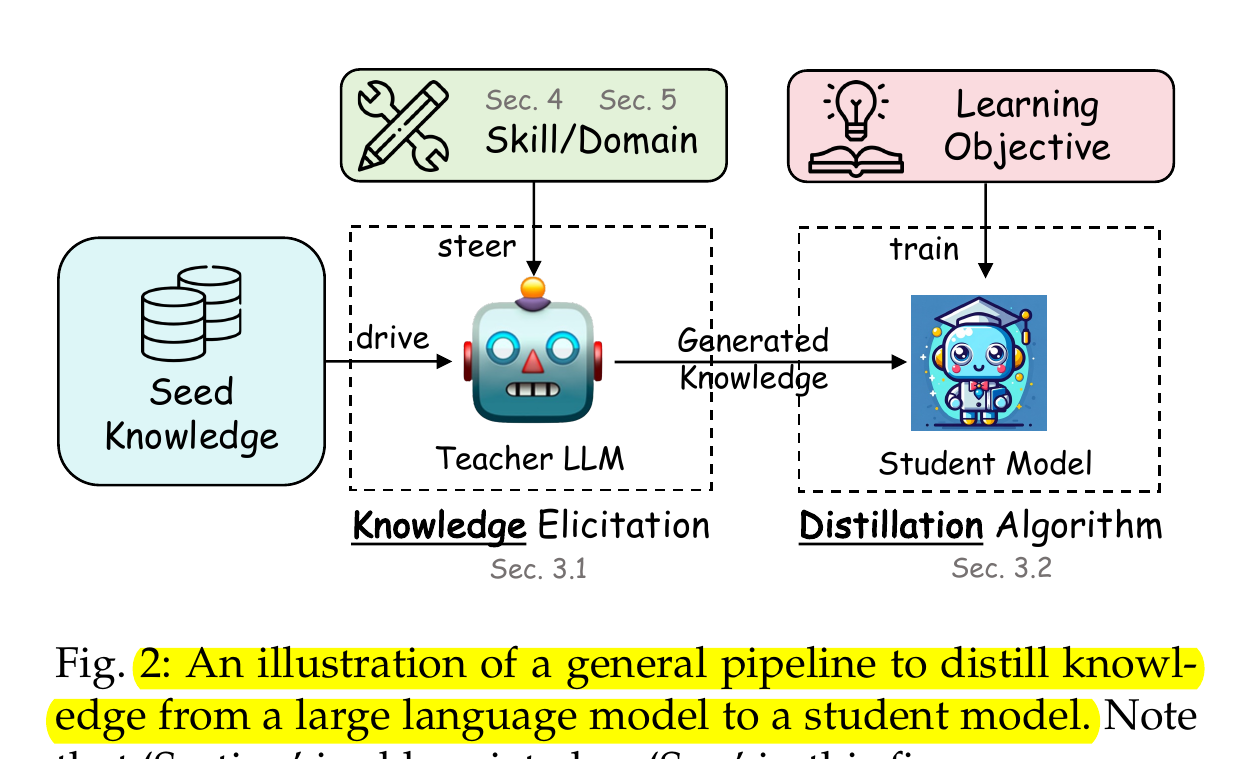
The teacher-student paradigm forms the foundation of distillation techniques. The teacher model, typically a large pre-trained model with high performance, guides the learning process of the student model, which is designed to be more compact and deployable in resource-constrained environments.
Knowledge transfer in distillation occurs through several mechanisms:
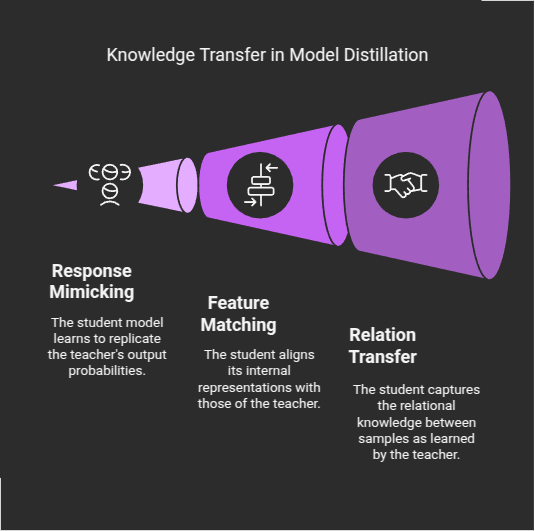
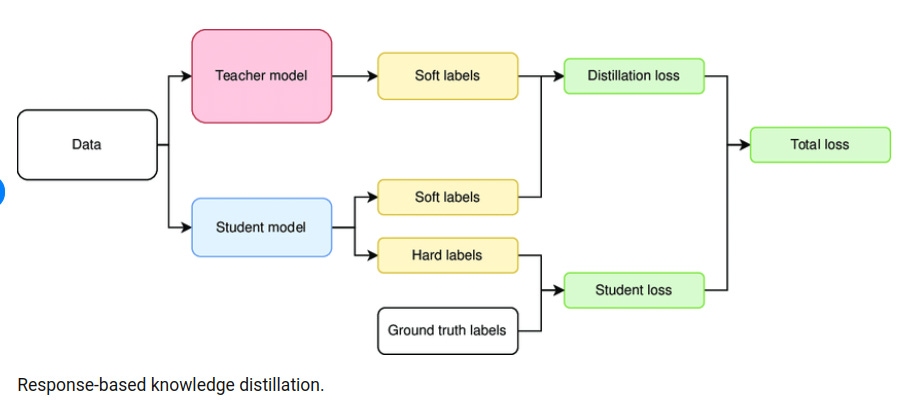
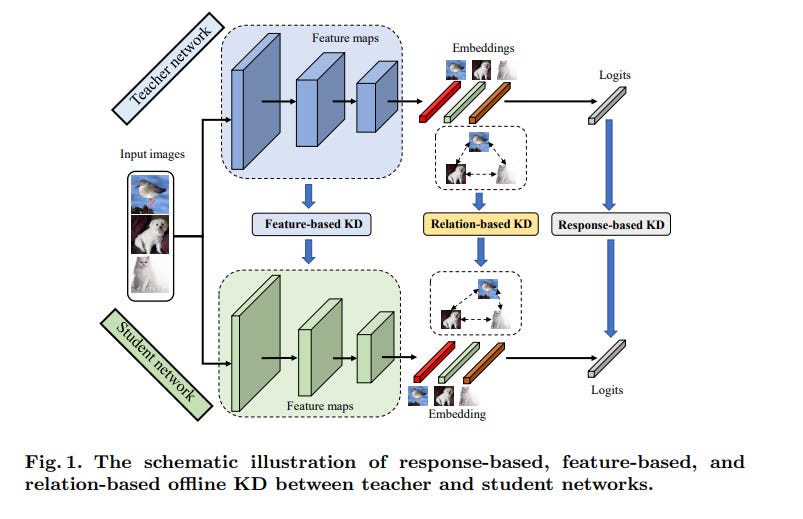
Response-based distillation: The student model learns to mimic the output probabilities (soft targets) produced by the teacher model, rather than just the hard class labels. These soft targets contain richer information about similarities between classes that aren't captured in one-hot encoded ground truth labels. Response-based knowledge distillation focuses on the final output logits. Here, the teacher’s prediction is transformed into a “soft target” distribution using a softmax function with an elevated temperature T.
Feature-based distillation: The student learns to match the internal representations or feature maps produced by the teacher model at various layers, capturing the intermediate knowledge representations.
Relation-based distillation: This approach focuses on transferring the relationships between different samples or features as learned by the teacher model.
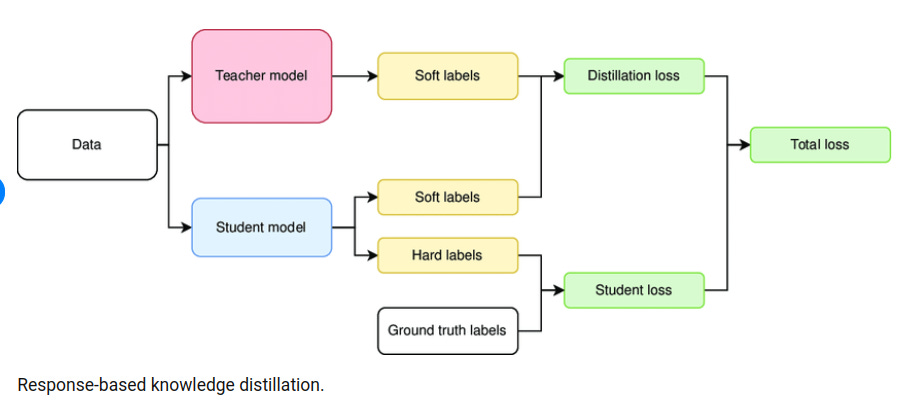
The distillation process typically involves a specialized loss function that combines a standard task loss (e.g., cross-entropy for classification) with a distillation loss that measures the difference between the teacher and student outputs or representations.
Evolution of Distillation Techniques
Since Geoffrey Hinton's seminal paper "Distilling the Knowledge in a Neural Network" in 2015, distillation techniques have evolved significantly. While the original approach focused primarily on matching output probabilities, modern distillation methods have expanded to include more sophisticated knowledge transfer mechanisms.
Recent advancements in 2024-2025 have pushed distillation techniques into new territories:
Multi-teacher distillation: Leveraging knowledge from multiple teacher models to create a more robust student model.
Self-distillation: A process where a model serves as its own teacher, with earlier versions of the model teaching later versions.
Online distillation: Teacher and student models are trained simultaneously rather than in sequence.
Offline distillation: The traditional approach where a pre-trained teacher model is used to train a student model.
Adversarial distillation: Incorporating adversarial training techniques to improve the robustness of distilled models.
The evolution of these techniques has been driven by the need to address specific challenges in model deployment, such as latency requirements, memory constraints, and energy efficiency considerations. As foundation models continue to grow in size and complexity, distillation has become an essential tool for making these models accessible and practical for real-world applications.
Recent Research Breakthroughs (2024-2025)
Representational Approaches to Distillation

Recent advancements in understanding how distillation affects model representations have provided significant insights into the mechanisms behind knowledge transfer. In March 2025, Baek and Tegmark from MIT published groundbreaking research titled "Towards Understanding Distilled Reasoning Models: A Representational Approach" that investigates how model distillation impacts the development of reasoning features in large language models.
Their research utilized a crosscoder trained on Qwen-series models and their fine-tuned variants to explore the unique features that emerge during distillation. The findings reveal that distilled models develop distinctive reasoning feature directions that can be used to steer models into different thinking modes:
Self-reflection features: Distilled models develop enhanced capabilities for evaluating their own outputs and reasoning processes.
Deductive reasoning features: Specific neural pathways emerge that specialize in logical inference and step-by-step problem solving.
Alternative reasoning features: Distilled models develop the ability to consider multiple solution paths simultaneously.
Contrastive reasoning features: The ability to compare and contrast different approaches becomes encoded in specific model dimensions.
Perhaps most significantly, Baek and Tegmark found that larger distilled models develop more structured representations, which correlate directly with enhanced distillation performance. This suggests that the benefits of distillation scale with model size, though in ways different from traditional scaling laws.
This research provides crucial insights into how distillation modifies model internals, contributing to improved transparency and reliability in AI systems. The ability to identify and manipulate specific reasoning features opens new possibilities for steering model behavior without additional training.
Quantification Methods for LLM Distillation

Quantifying the effectiveness and impact of distillation has been a persistent challenge in the field. In February 2025, Lee et al. addressed this gap with their paper "Quantification of Large Language Model Distillation", introducing a systematic framework for evaluating and quantifying model distillation.
The researchers proposed two novel methodologies:
Response Similarity Evaluation (RSE): This method compares outputs between original LLMs and student models across various prompts and contexts, providing a direct measure of behavioral similarity.
Identity Consistency Evaluation (ICE): This innovative approach adapts the GPTFuzz framework to craft prompts that bypass LLMs' self-identity, revealing identity information accidentally learned during distillation.
Their experiments yielded several key insights:
Base LLMs show higher distillation degrees compared to aligned LLMs, suggesting that initial training plays a crucial role in determining knowledge transfer levels.
Most well-known closed-source and open-source LLMs exhibit high distillation degrees, with notable exceptions being Claude, Gemini, and Doubao.
The degree of distillation correlates with model size, with larger student models more closely resembling their teachers.
This quantification framework addresses the opacity of the distillation process and provides a systematic approach to improve transparency. The researchers call for more independent LLM development and increased transparency in model training and distillation processes to improve robustness and safety.
Branch-Merge Distillation

A significant innovation in distillation techniques emerged in March 2025 with the introduction of the Branch-Merge distillation approach by researchers at Qiyuan Tech and Peking University. Their paper "TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation" presents a novel two-phase approach to enhance model compression:
Branch Phase: Knowledge from a large teacher model is selectively distilled into specialized student models via domain-specific supervised fine-tuning (SFT). This allows each student model to develop expertise in particular domains.
Merge Phase: These specialized student models are then merged to enable cross-domain knowledge transfer and improve generalization capabilities.
The researchers validated their approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, demonstrated remarkable performance improvements across multiple benchmarks:
Mathematics: +5.5 points
Coding: +4.4 points
Science: +2.9 points
Most impressively, TinyR1-32B-Preview achieved near-equal performance to the much larger DeepSeek-R1 on the AIME 2024 mathematics competition benchmark.
This approach represents a significant advancement over traditional distillation methods, which often fail to achieve high accuracy when reducing model size. The Branch-Merge technique provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and training time.
Domain-Specific Distillation for Speculative Decoding

Speculative decoding has emerged as an effective method for accelerating inference in large language models, but its effectiveness diminishes when applied to domain-specific models due to domain shift. In March 2025, Hong et al. from SambaNova Systems addressed this challenge in their paper "Training Domain Draft Models for Speculative Decoding: Best Practices and Insights".
The researchers systematically investigated knowledge distillation techniques for training domain-specific draft models to improve speculation accuracy. Their comprehensive analysis compared:
White-box vs. Black-box distillation: White-box approaches, which utilize the target model parameters, consistently outperformed black-box methods by 2% to 10% across domains.
Online vs. Offline distillation: Offline distillation, where a pre-trained teacher model is used, consistently outperformed online distillation by 11% to 25%.
Data accessibility scenarios: The researchers explored three scenarios:
Historical user queries (ideal but often unavailable)
Curated domain-specific data
Synthetically generated alignment data
Their experiments across Function Calling, Biology, and Chinese domains revealed that synthetic data can effectively align draft models, achieving 80% to 93% of the performance of training on historical user queries.
This research provides practical guidelines for training domain-specific draft models under varying data constraints, offering a valuable reference for improving inference efficiency in domain-specific LLM applications. The findings are particularly relevant for organizations deploying specialized models that require both accuracy and computational efficiency.
Distillation in Digital Pathology
The application of distillation techniques to specialized domains has yielded remarkable results in healthcare. In January 2025, Dop et al. published "Distilling foundation models for robust and efficient models in digital pathology", exploring the distillation of large foundation models for digital pathology applications.
The researchers distilled H-Optimus-0, a Vision Transformer-giant (ViT-g) with over one billion parameters, into a smaller ViT-Base of just 86 million parameters. The resulting distilled model, H0-mini, achieved:
Competitive performance: Ranked 3rd on the HEST benchmark and 5th on the EVA benchmark, nearly matching much larger foundation models.
Superior robustness: Significantly outperformed other state-of-the-art models in robustness to variations in staining and scanning conditions on the PLISM dataset.
Reduced computational requirements: Achieved these results with approximately 8% of the parameters of the original model.
This research demonstrates that distillation can be particularly valuable in specialized domains like medical imaging, where both performance and efficiency are critical. The improved robustness to variations in sample preparation and digitization is especially significant for clinical deployment, where such variations are common and can impact diagnostic accuracy.
The success of H0-mini opens new perspectives for designing lightweight and robust models for digital pathology without compromising performance, potentially accelerating the adoption of AI in clinical settings where computational resources may be limited.
PyTorch Implementation Approaches
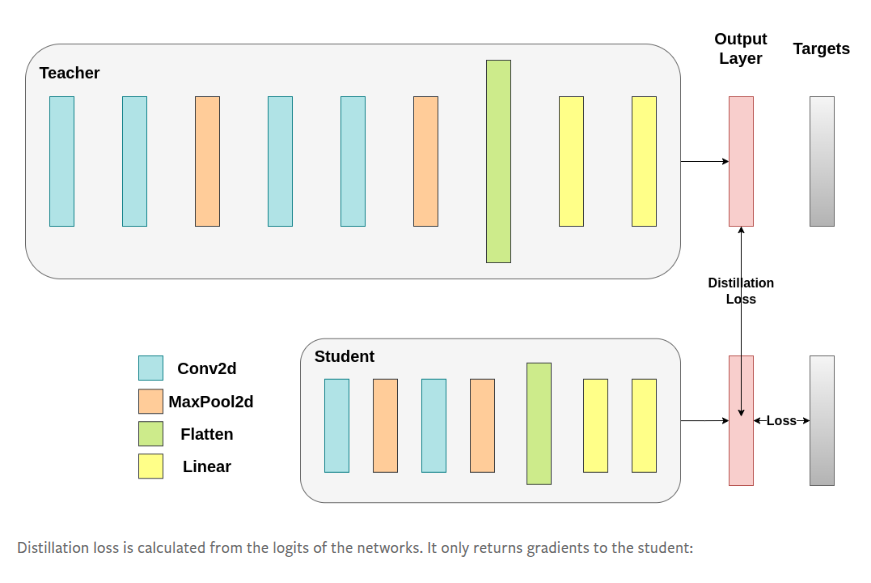
The official PyTorch documentation released an updated Knowledge Distillation Tutorial in January 2025, providing comprehensive guidance on implementing distillation techniques.
The PyTorch approach to distillation focuses on three key aspects:
Model Architecture Modification: PyTorch enables easy extraction of hidden representations from both teacher and student models. This is accomplished by modifying model classes to expose intermediate activations, which can then be used for feature-based distillation. The framework allows developers to:
Extract representations from specific layers
Compare activations across different architectural designs
Implement custom knowledge transfer mechanisms
Custom Loss Functions: PyTorch's dynamic computational graph makes it straightforward to implement complex distillation loss functions. A typical implementation combines:
A standard task loss (e.g., cross-entropy for classification)
A distillation loss measuring the difference between teacher and student outputs
Optional feature matching losses for intermediate representations
Training Loop Customization: The framework provides complete control over the training process, allowing developers to:
Implement temperature scaling for softening probability distributions
Balance multiple loss components with adjustable weights
Apply different optimization strategies to different parts of the model
A significant advantage of PyTorch's implementation is its support for dynamic computational graphs, which facilitates experimentation with different distillation techniques without requiring model redefinition.
TensorFlow Implementation Approaches
TensorFlow offers robust support for model distillation with an emphasis on production deployment and scalability. Recent updates to TensorFlow's distillation capabilities have focused on making the process more accessible and efficient.
TensorFlow's approach to distillation typically involves:
Model Subclassing: Using TensorFlow's Keras API, developers can create custom model classes that expose intermediate activations for distillation purposes. This approach allows for:
Clean separation between model definition and distillation logic
Reusable components for different distillation scenarios
Integration with TensorFlow's extensive deployment ecosystem
Custom Training Loops: TensorFlow 2.x's eager execution mode enables flexible training procedures that can incorporate multiple loss functions and complex knowledge transfer mechanisms. Key components include:
tf.GradientTapefor tracking operations and computing gradientsCustom metrics for monitoring distillation performance
Integration with TensorFlow's distributed training capabilities
Deployment Optimization: TensorFlow excels in optimizing distilled models for deployment across various platforms:
Quantization-aware training to further reduce model size
Integration with TensorFlow Lite for mobile and edge deployment
Support for TensorFlow Serving in production environments
TensorFlow's implementation approach is particularly valuable for organizations looking to deploy distilled models at scale, with strong support for model optimization and serving infrastructure.
Framework-Agnostic Techniques
Beyond specific framework implementations, several framework-agnostic techniques have emerged that can be applied regardless of the underlying deep learning library. These approaches focus on the conceptual aspects of distillation rather than implementation details.
Key framework-agnostic techniques include:
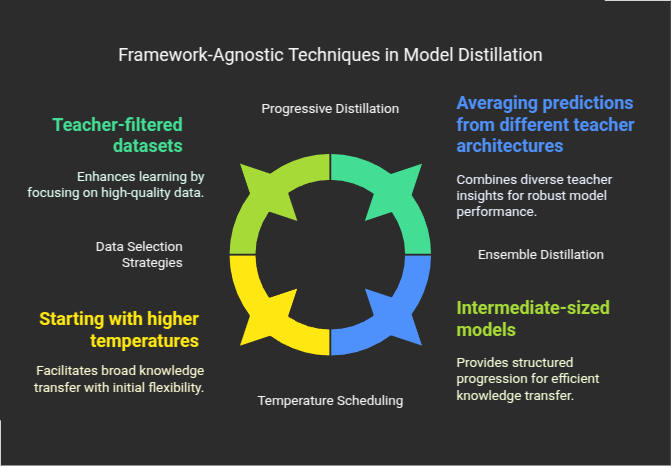
Data Selection Strategies: Carefully selecting the training data for distillation can significantly impact performance:
Using teacher-filtered datasets where only examples the teacher classifies correctly are used
Prioritizing examples where teacher and ground truth disagree to focus on edge cases
Generating synthetic examples that maximize knowledge transfer
Temperature Scheduling: Dynamically adjusting the temperature parameter during distillation:
Starting with higher temperatures to transfer general knowledge
Gradually reducing temperature to focus on specific class distinctions
Implementing curriculum learning approaches where difficulty increases over time
Ensemble Distillation: Combining knowledge from multiple teacher models:
Averaging predictions from different teacher architectures
Weighting teacher contributions based on their expertise in specific domains
Distilling specialized knowledge from domain-specific teachers
Progressive Distillation: Implementing distillation in stages:
Creating intermediate-sized models as stepping stones
Transferring knowledge through a chain of increasingly smaller models
Fine-tuning each stage before proceeding to the next
These framework-agnostic techniques complement the specific implementations in PyTorch and TensorFlow, providing conceptual approaches that can be adapted to any technical environment. The flexibility of these methods makes them particularly valuable for organizations working with custom frameworks or hybrid implementation approaches.
Industry Applications
Natural Language Processing
Model distillation has revolutionized the deployment of large language models (LLMs) in production environments, making advanced NLP capabilities accessible across a wider range of applications. The most notable example in 2024-2025 has been OpenAI's release of GPT-4o mini, a distilled version of GPT-4o that maintains impressive performance while requiring significantly fewer computational resources.
Edge Computing and Mobile Applications
Edge computing represents one of the most compelling use cases for distilled models, enabling sophisticated AI capabilities directly on devices without requiring cloud connectivity.
Key applications in this domain include:
Smartphone Features: Mobile device manufacturers have integrated distilled models to power features such as voice recognition, camera enhancements, and predictive text. These models operate efficiently within the power and thermal constraints of mobile devices while providing near-instantaneous responses.
IoT Devices: Smart home systems, industrial sensors, and other IoT devices have incorporated distilled models for local data processing and decision-making. This approach reduces bandwidth requirements and latency while enhancing privacy by minimizing data transmission to the cloud.
Autonomous Systems: Drones, robots, and other autonomous systems benefit from distilled models that can process sensor data and make decisions in real-time with limited computational resources. This capability is essential for applications requiring rapid responses to changing environments.
Wearable Technology: Health monitoring devices, smartwatches, and other wearables have implemented distilled models to analyze user data locally. These applications benefit from the reduced power consumption and processing requirements, extending battery life while maintaining functionality.
The deployment of distilled models at the edge represents a significant shift in AI implementation strategy, moving from centralized cloud processing to distributed intelligence. This approach not only improves performance and user experience but also addresses growing concerns about data privacy and network reliability.
Strategies for Startups
For startups operating with limited resources, model distillation offers a pathway to leverage advanced AI capabilities without prohibitive computational costs. Implementing distillation effectively requires strategic approaches tailored to startup constraints:
Leveraging Open-Source Teacher Models: Rather than training large models from scratch, startups can utilize publicly available pre-trained models as teachers. This approach significantly reduces the initial investment while still enabling the creation of efficient custom models. For example, using models like DeepSeek-R1 or open-source variants of GPT models as teachers can provide strong starting points for distillation.
Targeted Domain Specialization: Instead of creating general-purpose models, startups can focus distillation efforts on specific domains relevant to their business. As demonstrated in the research by Hong et al. (2025), domain-specific distillation can achieve impressive results even with synthetic data, allowing startups to create specialized models without extensive datasets.
Progressive Implementation: Startups can adopt an incremental approach to distillation:
Begin with smaller, focused models addressing specific use cases
Gradually expand capabilities as business requirements and resources grow
Prioritize high-ROI applications where improved efficiency directly impacts business outcomes
Cloud-Based Distillation: Utilizing cloud services for the distillation process itself can reduce upfront hardware investments:
Rent GPU instances only for the training phase
Implement spot instance strategies to reduce costs
Optimize hyperparameters on smaller datasets before full-scale distillation
Transfer Learning Optimization: Combining distillation with transfer learning can further reduce resource requirements:
Fine-tune pre-distilled models on domain-specific data
Implement parameter-efficient fine-tuning techniques like LoRA or adapter modules
Focus computational resources on layers most relevant to the target application
These strategies enable startups to implement sophisticated AI capabilities while maintaining lean operations and preserving capital for core business activities.
Resource-Constrained Environments
Implementing AI capabilities in resource-constrained environments presents unique challenges that distillation techniques are particularly well-suited to address.
Edge-Optimized Distillation: For deployment on edge devices with severe computational limitations:
Incorporate hardware constraints directly into the distillation objective
Combine distillation with quantization and pruning for extreme compression
Optimize for specific hardware accelerators available on target devices
Offline Capability Enhancement: For environments with limited or intermittent connectivity:
Distill models to operate effectively without cloud connectivity
Implement progressive enhancement approaches where basic functionality works offline
Develop synchronization mechanisms to update models when connectivity is available
Tiered Knowledge Transfer: For deployment across heterogeneous environments:
Create families of distilled models with varying size-performance tradeoffs
Implement dynamic model selection based on available resources
Develop knowledge sharing mechanisms between devices with different capabilities
Low-Power Operation: For battery-powered or energy-constrained settings:
Optimize distillation to prioritize energy efficiency alongside accuracy
Implement adaptive computation techniques that adjust model complexity based on battery status
Develop specialized activation functions and operations optimized for low-power hardware
Minimal Data Footprint: For environments with storage limitations:
Distill models to minimize not just computational requirements but also memory usage
Implement parameter sharing techniques across model components
Develop compression strategies for both model weights and activations
These approaches enable the deployment of AI capabilities in environments previously considered impractical for advanced models, from remote IoT sensors to humanitarian applications in regions with limited infrastructure.
ROI Analysis of Distillation Techniques
Evaluating the return on investment for distillation implementations requires considering multiple factors beyond simple accuracy metrics.
Total Cost of Ownership Calculation: A comprehensive TCO analysis should include:
Initial distillation costs (computational resources, engineering time)
Deployment infrastructure requirements
Ongoing operational expenses (power consumption, maintenance)
Performance impact on downstream business processes
Performance-Efficiency Tradeoffs: Quantifying the relationship between model size reduction and performance:
Establish minimum viable performance thresholds for specific applications
Identify diminishing returns points where further compression yields minimal efficiency gains
Develop application-specific metrics that balance accuracy with resource utilization
Scaling Economics: Understanding how distillation benefits change with deployment scale:
Calculate cost savings multipliers across distributed deployments
Assess infrastructure consolidation opportunities enabled by more efficient models
Project long-term savings from reduced hardware refresh requirements
Indirect Value Creation: Identifying benefits beyond direct cost reduction:
Improved user experience from reduced latency
New use cases enabled by local processing capabilities
Enhanced privacy and security from reduced data transmission
Sustainability improvements from lower energy consumption
A comprehensive ROI analysis typically reveals that distillation provides value well beyond the immediate computational savings, particularly when considering the full lifecycle of AI applications and their integration into broader business processes.
Challenges and Limitations
While model distillation offers significant benefits, it also presents several challenges and limitations that practitioners should consider when implementing these techniques.
Performance Trade-offs
Despite advances in distillation techniques, there remains an inherent tension between model size and performance capabilities:
Task Complexity Limitations: Distilled models typically show greater performance degradation on complex reasoning tasks compared to simpler pattern recognition tasks. As noted in Baek and Tegmark's research (2025), certain reasoning capabilities emerge only at specific model scales, making them difficult to fully transfer to smaller architectures.
Generalization Gaps: Student models often exhibit reduced generalization capabilities compared to their teachers, particularly when faced with out-of-distribution inputs or novel scenarios. This limitation can be particularly problematic in safety-critical applications where robust performance across diverse conditions is essential.
Diminishing Returns: The relationship between model size and performance is non-linear, with certain thresholds below which performance drops precipitously. Identifying these critical thresholds remains challenging and often requires extensive experimentation.
Feature Representation Limitations: As revealed in the representational studies by Baek and Tegmark (2025), distilled models develop different feature geometries compared to their teachers. While some of these differences can be beneficial, others may result in blind spots or biases not present in the original model.
Understanding these trade-offs is essential for setting realistic expectations and designing appropriate evaluation frameworks for distilled models.
Domain Adaptation Issues
Transferring knowledge across domains presents specific challenges in the distillation process:
Domain Shift Sensitivity: As demonstrated in Hong et al.'s research (2025) on speculative decoding, distilled models often show heightened sensitivity to domain shifts. When a generic model is distilled and then applied to a specialized domain, performance can degrade significantly without domain-specific adaptation.
Data Requirements: Effective domain adaptation often requires substantial domain-specific data, which may not be available in sufficient quantities. While synthetic data generation offers a partial solution, as shown in Hong et al.'s work, it typically cannot fully replace authentic domain data.
Multi-domain Balancing: When distilling models intended to perform across multiple domains, balancing performance across these domains becomes challenging. The Branch-Merge approach proposed by Sun et al. (2025) addresses this issue but introduces additional complexity to the distillation process.
Specialized Knowledge Transfer: Certain domains contain highly specialized knowledge that may be difficult to distill effectively, particularly when this knowledge is sparsely represented in the teacher model's parameters.
These domain adaptation challenges highlight the need for specialized distillation strategies when targeting specific application areas.
Technical Implementation Barriers
Implementing distillation effectively requires overcoming several technical challenges:
Architectural Mismatch: When teacher and student architectures differ significantly, establishing effective knowledge transfer mechanisms becomes complex. Different layer structures, attention mechanisms, or activation functions can complicate the mapping between teacher and student representations.
Optimization Difficulties: Distillation often involves balancing multiple loss components with different scales and convergence properties. Finding optimal weighting schemes and training schedules requires careful tuning and can significantly impact results.
Computational Requirements: While the end goal is a more efficient model, the distillation process itself can be computationally intensive, particularly when using large teacher models. This creates a barrier to entry for organizations with limited computational resources.
Evaluation Complexity: Assessing distillation quality goes beyond simple accuracy metrics and requires evaluating multiple dimensions of performance, including robustness, calibration, and specific capabilities. Developing comprehensive evaluation frameworks remains challenging.
Reproducibility Issues: The sensitivity of distillation to hyperparameters, initialization, and data ordering can make results difficult to reproduce consistently, complicating both research and production implementations.
Addressing these technical barriers requires specialized expertise and systematic approaches to distillation implementation.
Future Directions
As model distillation techniques continue to evolve, several promising research directions and industry trends are emerging that will shape the future of this field.
Emerging Research Areas
The cutting edge of distillation research is expanding in several exciting directions:
Self-Supervised Distillation: Researchers are exploring methods that reduce the dependence on labeled data for distillation. These approaches leverage self-supervised learning techniques to transfer knowledge between teacher and student models using unlabeled data, making distillation more accessible for domains where labeled data is scarce.
Adaptive Distillation: Rather than using fixed distillation strategies, adaptive approaches dynamically adjust the knowledge transfer process based on the student's learning progress. This includes techniques that focus on transferring knowledge about examples the student finds difficult or concepts it has yet to master.
Federated Distillation: Combining federated learning with distillation enables knowledge transfer across distributed devices without centralizing sensitive data. This approach is particularly promising for applications with privacy constraints, allowing organizations to leverage collective knowledge while maintaining data privacy.
Neural Architecture Search for Distillation: Automated methods for discovering optimal student architectures are gaining traction. These approaches systematically explore the design space to identify student models that maximize knowledge transfer efficiency while minimizing computational requirements.
Cross-Modal Distillation: Transferring knowledge between models operating on different modalities (e.g., vision to language, or language to audio) represents a frontier in distillation research. This approach enables the creation of efficient models that benefit from knowledge across different domains and data types.
These research directions promise to address current limitations and expand the applicability of distillation techniques to new domains and use cases.
Industry Adoption Trends
Several key trends are emerging in how industries are adopting and implementing distillation techniques:
Standardized Distillation Pipelines: Organizations are developing standardized workflows and tools for distillation, making the process more accessible to developers without specialized expertise. These pipelines integrate distillation into broader MLOps practices, enabling systematic application across multiple projects.
Hybrid AI Systems: Rather than viewing distilled models as standalone solutions, organizations are increasingly integrating them into hybrid systems that combine different approaches. These systems might use distilled models for routine queries while routing complex cases to larger models or human experts.
Continuous Knowledge Transfer: Moving beyond one-time distillation, organizations are implementing continuous knowledge transfer processes where student models are regularly updated based on the evolving knowledge of teacher models. This approach ensures distilled models remain current as new capabilities emerge.
Specialized Hardware for Distillation: Hardware manufacturers are developing specialized accelerators optimized for both the distillation process and the deployment of distilled models. These purpose-built solutions promise to further reduce the computational overhead of implementing distillation at scale.
Open Distillation Ecosystems: The emergence of open platforms for sharing distilled models and distillation techniques is democratizing access to these technologies. These ecosystems enable organizations to build upon existing work rather than starting from scratch, accelerating adoption across industries.
Code implementations
Distilling Llama3.1 8B into Llama3.2 1B using Knowledge Distillation
This is an official PyTorch guide, to showoing how you can use torchtune to distill a Llama3.1 8B model into Llama3.2 1B.
In Context of Knowledge Distillation
Teacher’s Role:
The teacher model's output probabilities (from softmax) represent the “true” or reference distribution that the student should learn from.Student’s Role:
The student model tries to mimic the teacher. By converting the student's logits into log probabilities usinglog_softmax, we can compute a loss that measures the difference between the student’s predictions and the teacher’s probabilities.Why KL Divergence?
The KL divergence (specifically, the forward KL divergence here) is computed by taking the expectation of the student’s log probability under the teacher’s probability distribution. Minimizing this loss encourages the student to adjust its output so that it becomes similar to the teacher's. Essentially, the student is "learning" to output probabilities close to the teacher’s.When computing KL divergence, the formulation requires the log of the student’s predicted probabilities. Here’s why using log_softmax for the student is preferred over applying softmax followed by a logarithm.
Hence The key loss function used in this KD approach is the Forward KL Divergence Loss, which measures the difference between the teacher’s and student’s output distributions. Here’s a simplified version of the implementation:
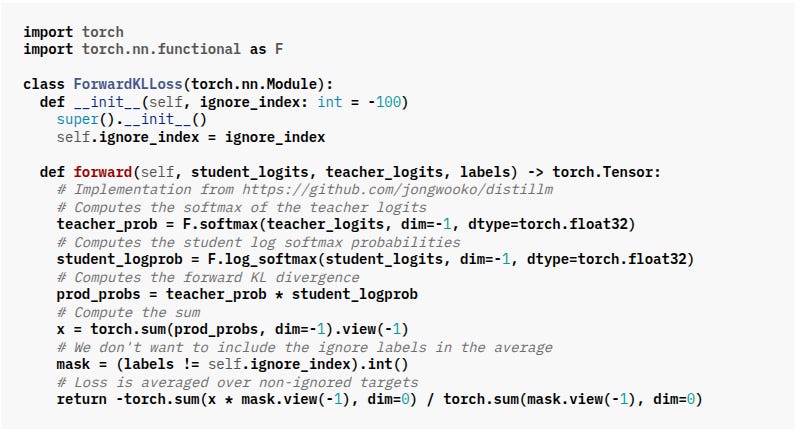
The
ForwardKLLossclass above implements the forward KL divergence loss—a common approach in knowledge distillation—to encourage the student model to mimic the teacher’s output distribution. Here’s a breakdown of how it works:Convert Logits to Probabilities:
Teacher: The teacher’s raw logits are passed through a softmax function to obtain a probability distribution over the classes.
teacher_prob = F.softmax(teacher_logits, dim=-1, dtype=torch.float32)What are logits?
Logits are the raw, unnormalized scores that a model outputs for each class. They can be any real numbers and aren’t yet probabilities.Why use softmax?
The softmax function converts these logits into probabilities that sum to 1. This is done by exponentiating each logit and then normalizing by the sum of all the exponentiated logits. This gives us a distribution over the classes.Student: The student’s logits are converted to log probabilities using log softmax. This prepares the student outputs for the KL divergence calculation.
Why not just softmax for the student as well?
For calculating KL divergence, we need the logarithm of the probabilities. Instead of first applying softmax and then taking the log (which could lead to numerical instability), we uselog_softmax. This function directly computes the log probabilities in a stable way.Mathematical Formulation:
The KL divergence between the teacher’s distribution PPP and the student’s distribution QQQ is defined as:
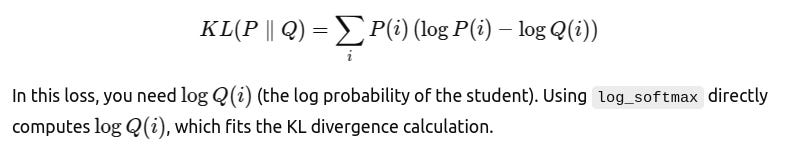
Numerical Stability:
Computing the softmax first and then taking the logarithm can lead to numerical instability (for example, issues with very small or very large numbers). The combined operationlog_softmaxis designed to be more numerically stable than performing softmax and log as separate steps.PyTorch’s KLDivLoss Expectation:
PyTorch’snn.KLDivLossexpects its input to be log probabilities and its target to be probabilities. Therefore, by usinglog_softmaxon the student’s logits, you ensure that the inputs are in the correct form for the loss function.How does log_softmax help?
It returns the logarithm of the softmax probabilities. These log probabilities are used to measure how well the student’s predicted distribution (its guesses) aligns with the teacher’s distribution.
student_logprob = F.log_softmax(student_logits, dim=-1, dtype=torch.float32)Compute the Expected Log-Probability: The loss calculates the element-wise product of the teacher’s probabilities and the student’s log probabilities. This effectively computes the expectation of the student’s log probability under the teacher’s distribution:
prod_probs = teacher_prob * student_logprob x = torch.sum(prod_probs, dim=-1).view(-1)In standard KL divergence, we would subtract the teacher's entropy, but since the teacher’s entropy does not depend on the student’s parameters, it can be ignored during optimization.
Masking and Averaging: Some tokens may be marked to be ignored (using an
ignore_index). A mask is applied to ensure that the loss only averages over valid tokens:
mask = (labels != self.ignore_index).int() return -torch.sum(x * mask.view(-1), dim=0) / torch.sum(mask.view(-1), dim=0)The negative sign converts the maximization of the expected log probability into a minimization problem. Essentially, minimizing this loss encourages the student to produce a probability distribution similar to that of the teacher.
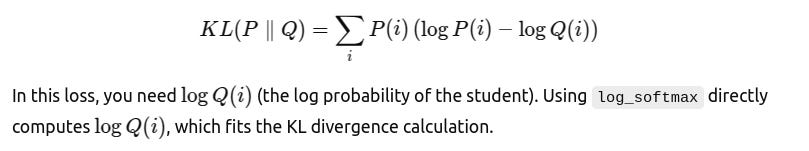
In summary: The ForwardKLLoss class guides the student model to align its output distribution with that of the teacher by computing the negative expected log probability of the student's predictions under the teacher’s distribution. This loss is averaged only over non-ignored tokens, making it a straightforward yet effective method for transferring knowledge from the teacher to the student model.
And the the KD Workflow with torchtune
Downloading Model Weights: Use torchtune’s command-line interface to download pre-trained weights for both teacher (Llama3.1-8B) and student (Llama3.2-1B) models.
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>Fine-Tuning the Teacher: It is beneficial to first fine-tune the teacher model (using LoRA) on your target dataset.
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_deviceRunning Knowledge Distillation: Once the teacher is fine-tuned, the student is distilled using torchtune’s KD recipe.
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_deviceExperimentation: The tutorial also shows how you can experiment with:
Fine-tuning either or both teacher and student models.
Adjusting hyperparameters such as the learning rate or the KD loss ratio (kd_ratio).