
🥉Yann LeCun presents Dynamic Tanh (DyT): A single tanh function can replace normalization and boost speed

Read time: 7 min 36 seconds
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (17-March-2025):
🥉 Yann LeCun presents Dynamic Tanh (DyT): A single tanh function can replace normalization and boost speed
🏆 Baidu, the google of China, releases two multimodal models, ERNIE 4.5: beats GPT 4.5 for 1% of price
📡 Mistral AI has introduced Mistral Small 3.1: multimodal, multilingual, Apache 2.0, the best model in its weight class
🧑🎓 Tutorial: Few-shot prompting with Gemini's API
🥉 Yann LeCun presents Dynamic Tanh (DyT): A single tanh function can replace normalization and boost speed

Yann LeCun and collaborators introduced DyT, a scaled tanh function that replaces normalization layers in deep models, significantly saving compute while matching or exceeding standard performance.
🔬 Core Idea
DyT is a simple function that limits how large or small a Transformer’s internal values can get, without needing to measure or adjust the batch statistics. Here’s how it helps:
Replaces Norm Layers: Instead of using LayerNorm or RMSNorm (which calculate averages and variations), DyT uses tanh(α * x). This has fewer calculations and still keeps your network’s values from blowing up.
Saves Compute: Since DyT doesn’t compute mean or variance, it cuts down on the extra work in every layer. Models often train and run faster as a result.
Keeps Values in a Good Range: Tanh naturally flattens very large positive or negative numbers, so no giant spikes appear. Around zero, it’s almost a straight line, so important small details remain intact.
α (Alpha) is Learnable: The model figures out how tight or loose the tanh curve should be. A bigger α squeezes values more; a smaller α behaves more gently.
Works Well Across Tasks: Whether it’s vision (ViT, ConvNeXt, DiT), language (LLaMA), speech (wav2vec), or DNA modeling (HyenaDNA, Caduceus), DyT consistently matches or beats normal normalization layers.
In short, DyT simplifies Transformers by removing the need for statistics-based layers, yet still preserves stable and efficient training.
Algorithm 1 Pseudocode of DyT layer.

DyT is a tiny layer that transforms its input using the tanh function. The constructor takes a dimension C and an initial alpha value. It creates one special learnable number alpha, which multiplies the incoming data, plus two arrays gamma and beta, which have one element per channel.
Inside the forward method, the input is first multiplied by alpha, then passed through tanh. Tanh takes any large positive or negative values and squashes them into a range between -1 and 1. That result is next scaled by gamma and shifted by beta on a per-channel basis.
The shape notation [B, T, C] means we have a batch (B) of sequences (T tokens each), with each token represented by C features. DyT uses these C features to decide how strongly to scale or shift them.
In effect, DyT squeezes the data to avoid huge spikes, then adjusts each channel so the model can still learn the ideal final output values for each token.
🏎️ Speed Gains
For large language models (e.g., LLaMA 7B), DyT trims normalization overhead by over 50%, cutting total training and inference time by up to 8% on high-end GPUs. This advantage grows as model widths increase.
📊 Comparable Performance
Experiments on Vision Transformers, LLaMA, wav2vec 2.0, DiT, and others show DyT meets or exceeds baselines without tricky hyperparameter tuning. For instance, DyT-based ViT-B hits 82.5% ImageNet accuracy vs. 82.3% with LayerNorm.
⚙️ Key Parameter α
DyT’s α aligns with input standard deviations. Larger models or higher learning rates often need smaller α to prevent divergence. For LLMs, splitting α initialization between attention blocks and other layers yields better loss.
How DynamicTanh Appears in the Code
They have published the Github and in there in many Transformer code paths (e.g. in main.py or model files), there is a line like
model = convert_ln_to_dyt(model)This step literally rewires any LayerNorm call into DyT. So the rest of the model trains the same way, but uses DyT instead of normal LayerNorm logic.
So that convert_ln_to_dyt(model) walks through every module in the model (all nested sub-layers, recursively looking into child layers). Whenever it finds a LayerNorm, it replaces that piece with a new DynamicTanh instance.
Since DynamicTanh has the same shape parameters (for example, how many channels or features), the rest of the model remains compatible. The end result is the same model structure, but everywhere LayerNorm appeared, you now get a tanh(α * x) with learnable scaling/offset, effectively switching out normalization with DyT.
🏆 Baidu, the google of China, releases two multimodal models, ERNIE 4.5: beats GPT 4.5 for 1% of price

🎯 The Brief
— ERNIE 4.5: beats GPT 4.5 for 1% of price
— Reasoning model X1: beats DeepSeek R1 for 50% of price.
China continues to build intelligence too cheap to meter. They emphasize upgraded language comprehension, logical reasoning, and coding abilities, claiming a major leap in affordable AI. Try the models directly here.
⚙️ The Details
ERNIE 4.5 refines language generation with stronger "EQ," less hallucination, and better logic. Baidu notes it excels at coding tasks and advanced communication.
Its pricing stands at $0.55 per million input tokens and $2.20 per million output tokens, reflecting an ultra-low cost approach.
ERNIE X1 is Baidu’s first "deep-think" model, handling complex tasks with a step-by-step method. Baidu positions it at half the price of DeepSeek’s R1 for similar reasoning power. Checkout the price comparison below.

📡 Mistral AI has introduced Mistral Small 3.1: multimodal, multilingual, Apache 2.0, the best model in its weight class

🎯 The Brief
Mistral AI releases Mistral Small 3.1 with 24B parameters, delivering 150 tokens/s throughput and 128k context window under Apache 2.0. It surpasses Gemma 3 and GPT-4o Mini in text, multilingual, and multimodal tasks.
⚙️ The Details
• This low-latency model accommodates instruction following, image understanding, and function calling. It handles multilingual content and boasts expanded context length for large-scale transcripts or documents.
• Capable of rapid function execution within automated or agentic workflows.
• Users can deploy it on a single RTX 4090 or a Mac with 32GB RAM, making it appealing for on-device scenarios.
• The base and instruct checkpoints are available, enabling further customization or fine-tuning in specialized domains.
• Licensing is Apache 2.0, ensuring broad usage rights.
• For enterprise-grade deployments or private inference, Mistral AI offers a dedicated infrastructure.
• Access options include Huggingface downloads, Mistral’s developer playground, Google Cloud Vertex AI, and soon NVIDIA NIM plus Microsoft Azure AI Foundry.
🧑🎓 Tutorial: Few-shot prompting with Gemini's API
When you send messages to an LLM, it is often best to show it how you want it to respond before you ask for something new. Here is a quick snippet to show this Few-shot prompting with Gemini's API.
In this code, I show examples by pairing a “user” message (which includes a PDF) with a “model” message (which includes the summary). By doing so, you offer the model a reference of what an ideal answer looks like for each file. Once you have provided a few of these sample interactions, the model can infer the style and content it should use when responding to new queries.

Here, the strategy is using alternating "user" and "model" messages with few-shot examples. It mimics Gemini's training data format: Gemini and similar large language models are often trained on conversational datasets where interactions are structured as alternating turns between a "user" and a "model".
So by alternating “user” → “model” messages for each example, you preserve the exact interaction style the model was trained on.
The model sees real examples of the “question + answer” format.
When it gets a new “user” prompt (the third PDF), it tries to match the pattern set by the example prompts and answers.
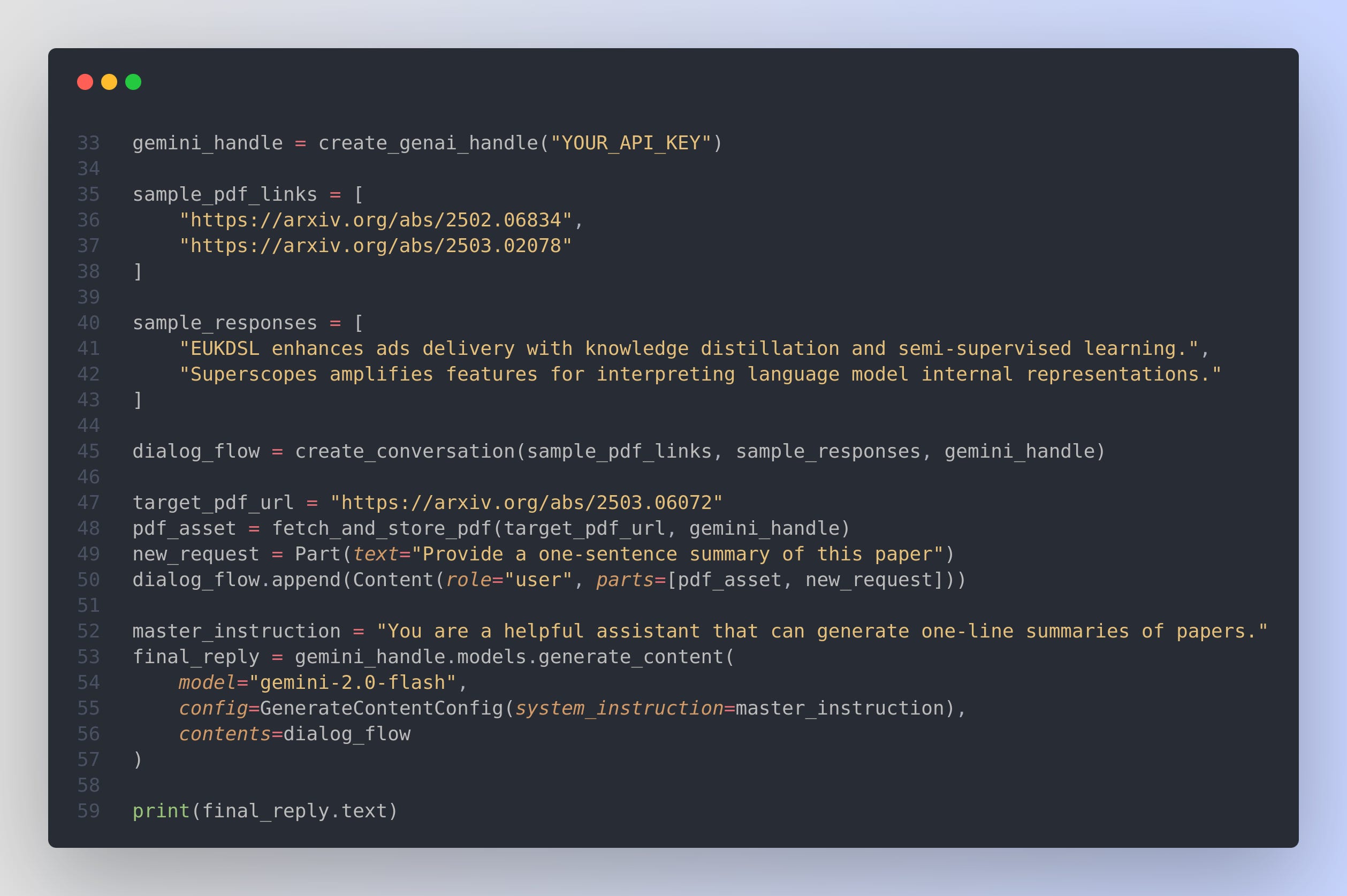
The code creates a “conversation flow” that toggles between “user” and “model” roles. Each PDF is uploaded and represented as a Part object, while the text instruction (“Provide a one-sentence summary…”) is another Part. For every example PDF, you combine the file and the instruction into a single user message, and then provide the exact answer you want the model to learn as a model message. This pattern tells the system exactly how the dialogue should unfold.
When you then supply a fresh PDF without a pre-written model response, the LLM sees the previous pattern and tries to match it. Because it recognizes you are making the same request (“Provide a one-sentence summary of this paper”) but now without a set response, it produces a new one in a similar format. This approach is called few-shot prompting because you give the model a few examples of the user’s request and the model’s ideal answer, so it can replicate the behavior.
That’s a wrap for today, see you all tomorrow.